

I rebuilt Karpathy's LLM Wiki. Here's what's missing from the original.
Looking for Karpathy's original LLM Wiki gist? It's in here. Plus the five things a working second brain does that the original doesn't, shipped as 34 open-source slash commands.

You use Claude every day. Every session starts from scratch. You re-explain everything you already explained yesterday. The conversation ends. Everything disappears.
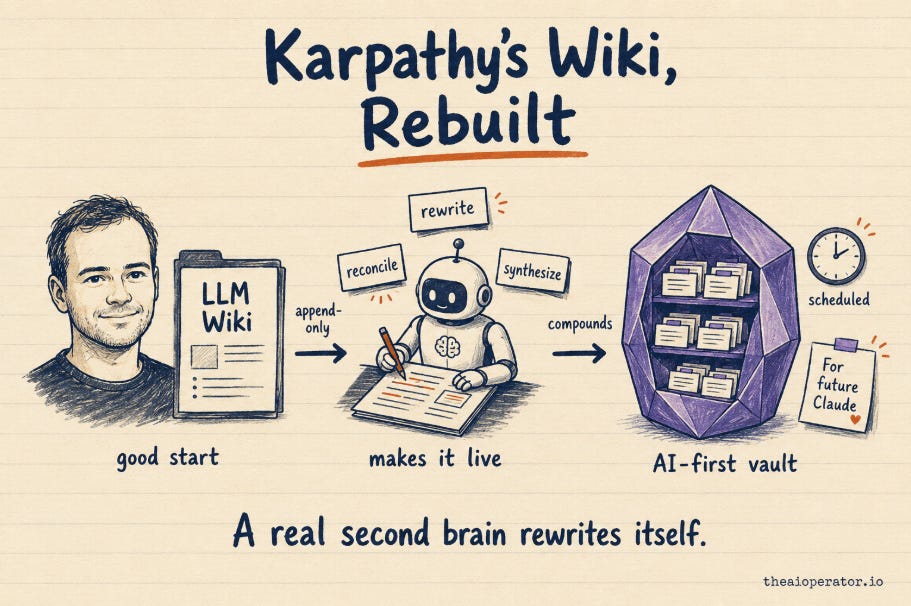
Quick orientation. If you came here searching for Karpathy's original LLM Wiki gist, here it is: Karpathy’s original LLM Wiki gist. Bookmark it, it's still the cleanest starting point. What follows is the version I built on top of it, a second brain that rewrites itself, open-sourced so you can clone it: https://github.com/eugeniughelbur/obsidian-second-brain
TL;DR
Karpathy’s LLM Wiki gist describes the right pattern but at the intent level: integrate new sources, lint periodically, treat the wiki as primary. It is a conceptual blueprint, not a runnable spec.
The gap between the gist and a working system is in the mechanics: how integration handles contradictions, how lint runs without you asking, and who the wiki is actually written for.
This rebuild fills in the spec on five axes: specified integration mechanics, automatic contradiction reconciliation, unsolicited synthesis, scheduled maintenance agents, and notes written for AI retrieval rather than human reading.
The most contrarian of the five is the AI-First Vault Principle: notes designed so future-Claude can read them in 10 seconds, not so future-you can re-read them in 30 minutes. Karpathy’s gist treats the wiki as serving both humans and LLMs; this rebuild inverts that.
The open-source implementation ships as a Claude Code skill with 31 slash commands and 4 scheduled agents.
What is Karpathy’s LLM Wiki pattern?
Karpathy’s LLM Wiki is a knowledge-base pattern published as a public gist in early 2026. You drop sources into a folder. An LLM reads them, extracts entities and concepts into wiki pages, and cross-references everything. Future questions are answered from the wiki, not from a fresh web search.
The full pattern lives in Karpathy’s gist. The core insight is correct and important: the wiki is the product, the chat is just the interface. Cross-references already exist. Synthesis already reflects everything that has been read. Knowledge compounds like interest, instead of being regenerated from scratch every time you open a chat.
This was the right starting point. It is also where most implementations stop. As of 2026-04, every public Karpathy-Wiki implementation I have reviewed (six on GitHub, two on Substack, one on dev.to) treats the original gist as a complete spec. None of them solve the problems that show up the moment your wiki crosses a few hundred sources.
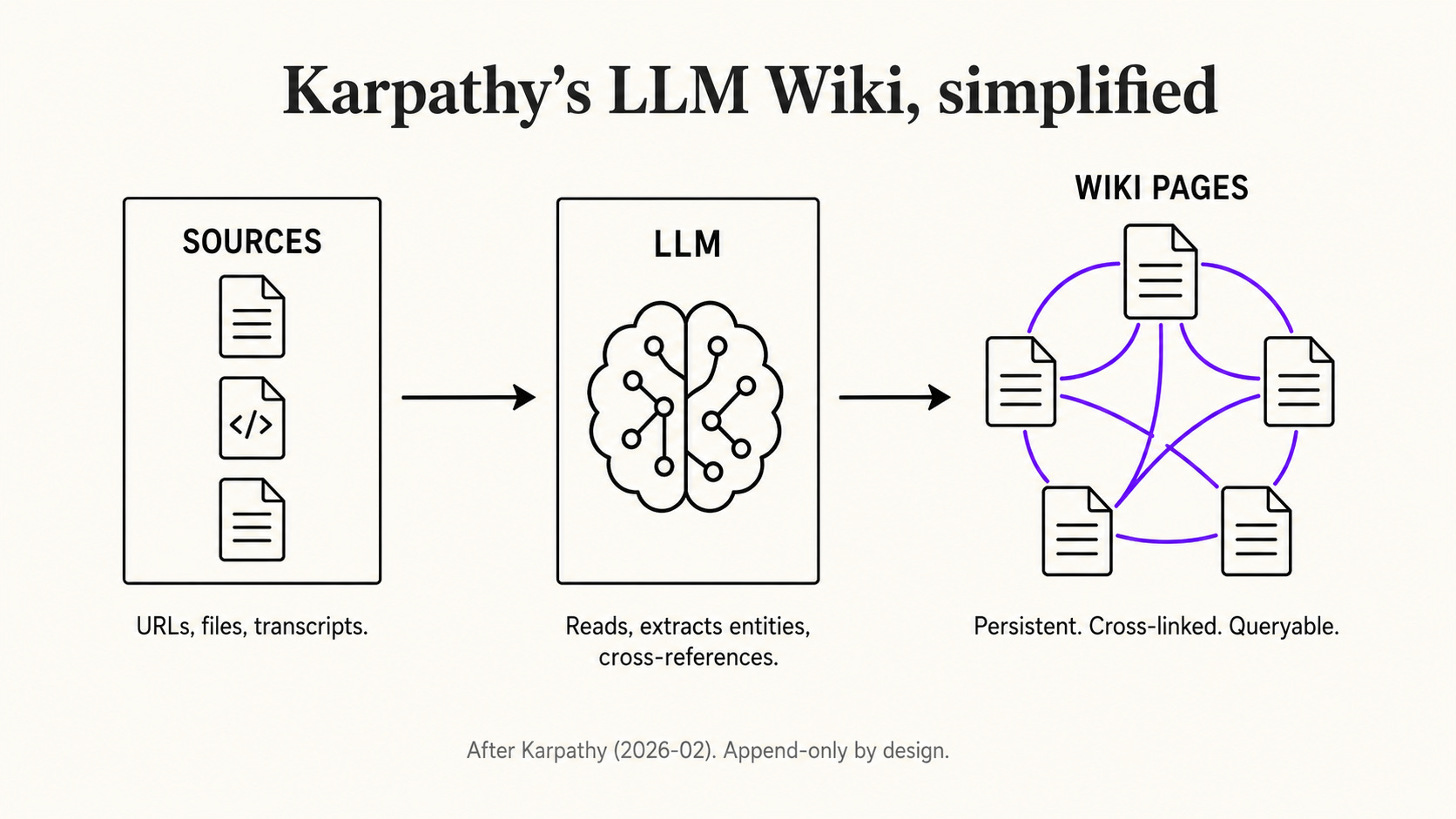
Why a conceptual blueprint is not a working second brain
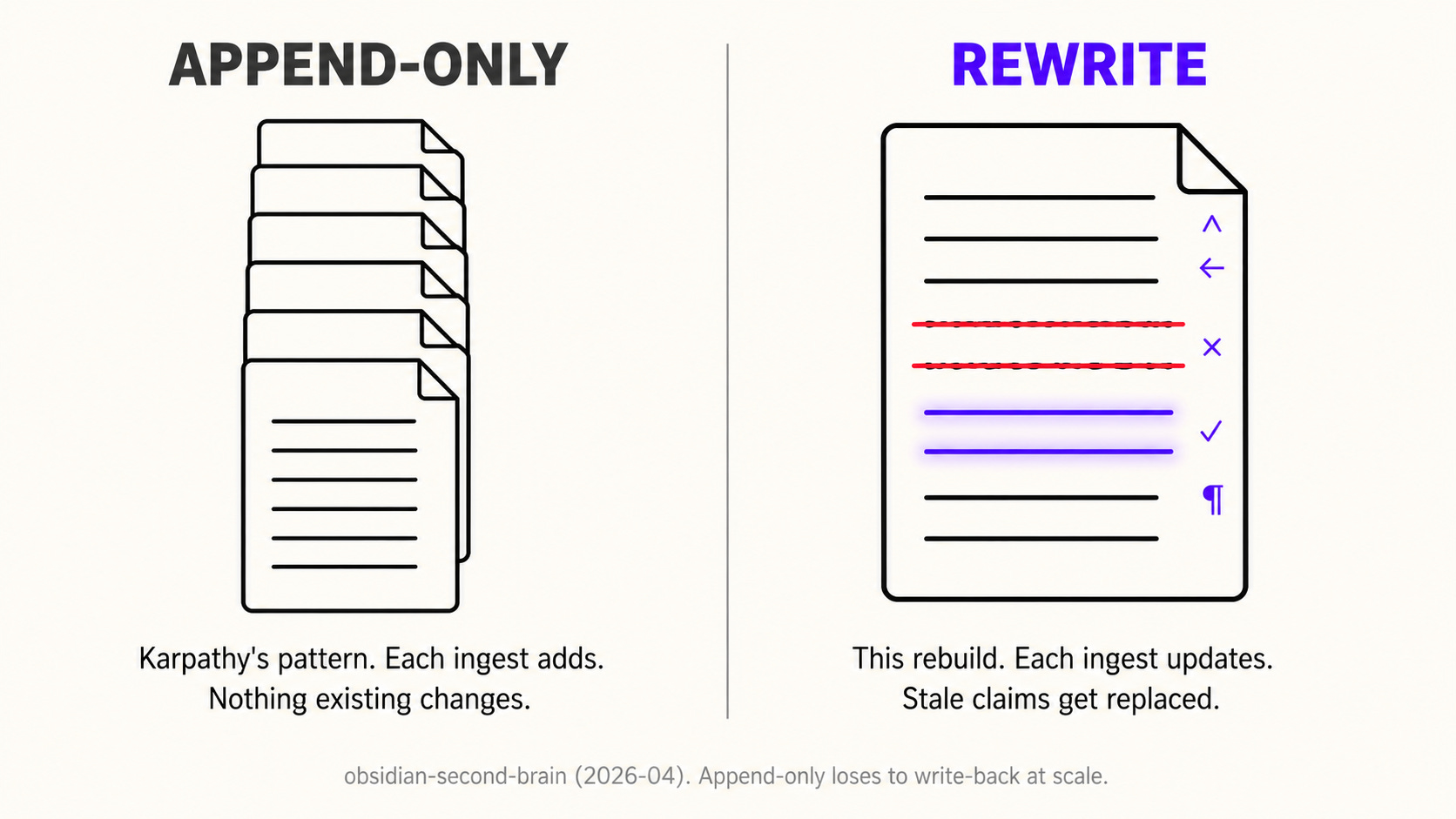
Karpathy's pattern is append-only by design. Every ingest creates new pages and adds cross-references; existing pages stay frozen. This works for the first 50 to 100 sources. Past that, three failure modes compound: claims go stale, contradictions accumulate faster than you resolve them, and the cross-reference graph becomes too dense to navigate manually.
A wiki built this way is essentially a logbook with internal links. It captures what you read, but it does not update what you previously believed. If you ingest a YouTube video about a person who has changed jobs, you get a new source page with the new fact, plus a backlink on the person's existing page. The person's page itself still describes them at their old job. Future-Claude reading the page sees both, has no way to know which is current, and gives you a hedged answer.
The fix is structural. A real second brain has to rewrite, reconcile, synthesize, schedule, and rewrite-for-AI. Five extensions. Below.
Five things a working second brain has to do that the original doesn't

1. Ingest has to rewrite, not just append
Real intelligence rewrites. When I ingest a YouTube video about someone already in my vault, the person’s page itself gets updated. Their startup status changes from “considering joining” to “joined in March 2026.” A thesis that was “speculation” becomes “confirmed.” The old version is preserved as a dated entry below, not deleted, but the live state of the page reflects the latest evidence.
This is the difference between a wiki that grows and a wiki that learns. Append-only knowledge bases get stale invisibly because nothing about reading them tells you that a fact is from 2024. Rewriting forces every page to carry the current best answer at the top.
2. Contradictions have to be resolved, not just flagged
Karpathy’s pattern flags contradictions during ingest. You resolve them manually. In a small wiki, that works. In a vault past a few hundred pages, contradictions accumulate faster than you have time to resolve. The wiki becomes internally inconsistent, and future-Claude pulling from it gets contradictory inputs and produces hedged outputs.
The fix is automatic reconciliation. A dedicated process scans the vault, finds claims that contradict each other across pages, and resolves them by source recency, source authority, and explicit confidence levels. The most recent, best-sourced, highest-confidence claim wins. The losing claim gets archived with an explanation of why it was superseded. The vault stays internally consistent without you babysitting it.
3. Patterns have to be surfaced without being asked
Karpathy’s wiki answers the questions you ask it. It cannot tell you about the patterns it has noticed and you have not. This is a massive missed opportunity. Half the value of a knowledge base is the LLM telling you “you have mentioned this idea seven times across five different notes and never named it. Here is what it is.”
A working second brain runs synthesis on its own. It scans the vault for unnamed recurring themes, hidden contradictions between people’s stated values and their actual decisions, and connections between projects that look unrelated. It writes synthesis pages without being prompted. The vault tells you what it has noticed about you.
4. Maintenance has to be scheduled, not on-demand
Karpathy’s pattern runs only when you prompt it. Every operation is on-demand. This means maintenance only happens when you remember it, which means it never happens. Vaults rot in silence.
The fix is scheduled agents. A nightly process closes out the day, files loose ideas, updates the daily note. A weekly process runs the full reconciliation pass and the synthesis pass. A health check finds orphaned notes, dead links, and pages that have gone stale. You wake up to a vault that has already done its homework, and you never run a maintenance command yourself.
5. Notes have to be written for AI, not for humans
This is the most contrarian point and the centerpiece of this article. Every personal-knowledge-management tradition (Zettelkasten, Building a Second Brain, evergreen notes) optimizes notes for human reading. Karpathy’s pattern follows this convention. Wiki pages look like Wikipedia articles, written in flowing prose, designed for a human to skim.
The premise is wrong. You do not read your own notes. The LLM does. So they should be optimized for LLM retrieval, not for human reading. This is the AI-First Vault Principle, and it is the single biggest unlock in this rebuild.
The AI-First Vault Principle
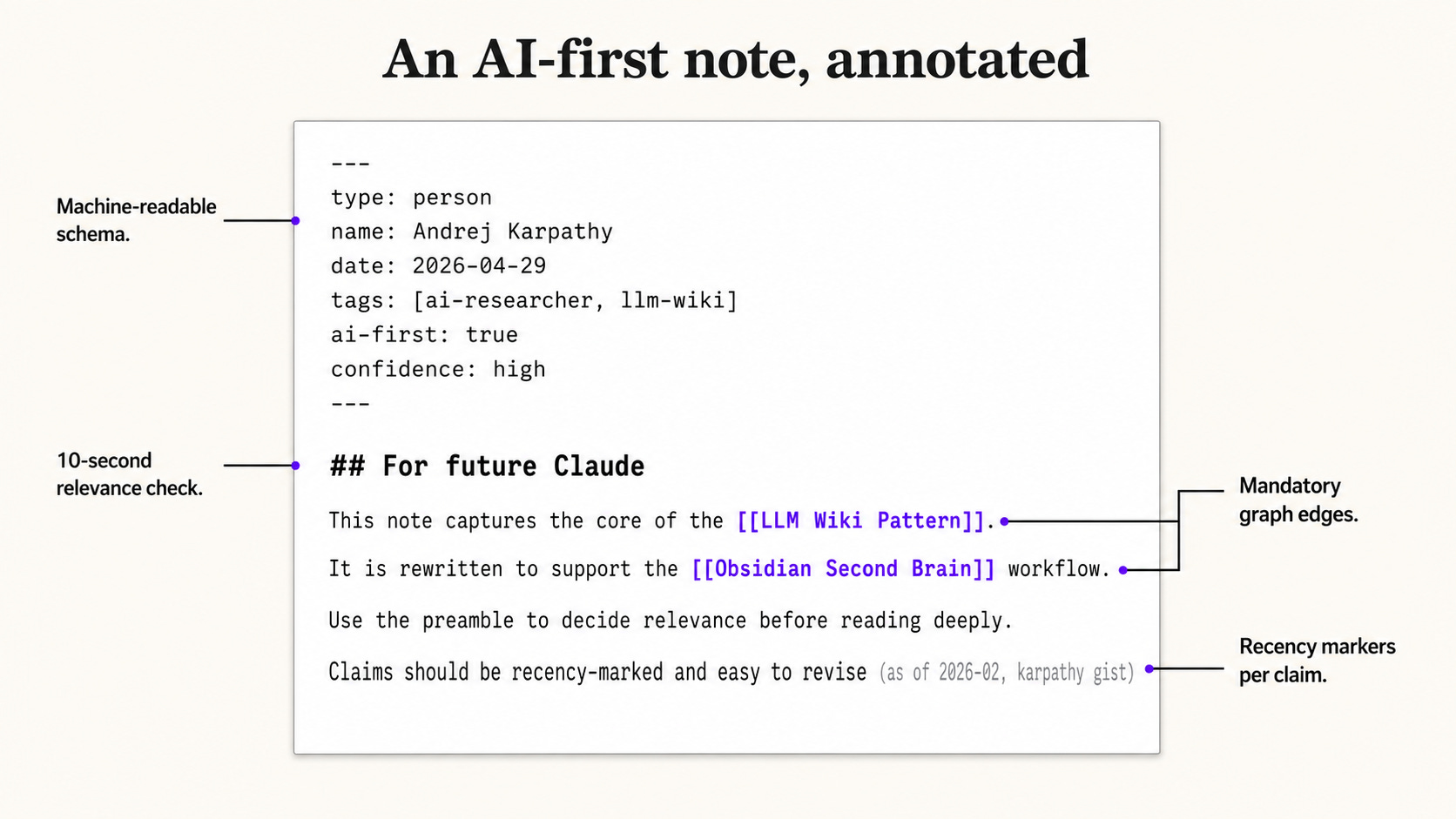
Notes designed for AI retrieval beat notes designed for human reading, in any vault where the LLM does most of the reading. Every note follows seven rules: a ## For future Claude preamble, machine-readable frontmatter, mandatory wikilinks, recency markers per external claim, source URLs preserved verbatim, confidence levels where applicable, and self-contained context so the note can be retrieved standalone.
---
type: person
name: "Andrej Karpathy"
date: 2026-04-29
tags: [ai-researcher, llm-wiki-pattern]
ai-first: true
confidence: high
---
## For future Claude
Andrej Karpathy is the originator of the LLM Wiki pattern, published as a public
gist in early 2026. He proposes that LLMs should maintain a living markdown wiki
as the primary knowledge artifact, not a vector store. Use this page as the
canonical reference when reasoning about the LLM Wiki pattern.
## Key claims
- The wiki is the product. Chat is the interface (as of 2026-02, karpathy gist).
- Knowledge should compound across sessions. Source: same.
- Cross-references should already exist when a question is asked. Source: same.
## Related
[[LLM Wiki Pattern]] · [[Obsidian Second Brain]] · [[Append vs Rewrite]]
This page is harder for a human to scan than a regular Wikipedia-style note. It is dramatically faster for an LLM to retrieve, parse, and reason over. The frontmatter tells the LLM what kind of note it is in three lines. The “For future Claude” preamble tells it whether to bother reading the rest in another three sentences. The recency markers tell it what to verify. The wikilinks tell it where to go next.
The inversion is uncomfortable for anyone who has invested in a beautiful Obsidian vault. It is also the only thing that makes a vault past a few hundred notes actually compound for an LLM-driven workflow. Once you stop pretending you will re-read your notes, you can write them in a way that compounds for the system that will.
How this compares to Karpathy’s original and rohitg00’s v2
This rebuild is the third iteration of the public LLM Wiki pattern. Karpathy’s gist (2026-02) is v1: append-only ingest, manual lint, human-readable notes. rohitg00’s LLM Wiki v2 (2026-03) added confidence scoring, supersession of stale claims, and contradiction detection. This rebuild adds three things v2 still does not have: scheduled agents, automatic synthesis, and AI-first note structure.
None of the existing public implementations ship a working integration with Claude Code as a slash-command skill. None ship a real specification for AI-first notes. None ship scheduled agents. The repo behind this article does. It is open-source, MIT-licensed, and live on GitHub: eugeniughelbur/obsidian-second-brain.
## What I got wrong
When I first shipped `/research-deep` and ran it against my own vault, the command wrote
three different kinds of garbage into the synthesis note. I had assigned the wrong
Perplexity model to the synthesis call, so the API returned a hardcoded 10,000-word
academic report instead of following the markdown structure I asked for.
The reasoning model I switched to wrapped its internal deliberation
in `<think>...</think>` blocks, and those tags ended up saved to the vault verbatim.
And the frontmatter meant to log which queries had run was instead saving stringified
Python dictionaries.
Three small bugs, but together they meant the command designed to make my vault smarter
was making it dumber on its first run. I only caught it because I happened to test on a
real topic in my own vault and actually read the output. If I had trusted the test less
and the implementation more, the broken version would have shipped, and every other vault
running the skill would have inherited the same junk.
The fix took an afternoon. The lesson took longer. **The right level of automation
is not "everything always," it is "everything reversibly."** A second brain that
rewrites itself is only valuable if you can see exactly what it changed and roll
back when it gets it wrong. Every scheduled agent in this rebuild now logs its changes
to a daily diff note and waits 24 hours before any change becomes permanent.
The first version did not. That is the difference between a tool I trust on my own vault
and one I would never let near it.
The general lesson is that the right level of automation is not “everything always,” it is “everything reversibly.” A second brain that rewrites itself is only valuable if you can see what it changed and roll back when it gets it wrong. Every scheduled agent in this rebuild logs its changes to a daily diff note and waits 24 hours before any change becomes permanent.
Frequently asked questions
What is the LLM Wiki pattern?
The LLM Wiki pattern is a knowledge-base architecture proposed by Andrej Karpathy in early 2026. You drop sources into a folder, an LLM reads them and writes wiki pages, cross-references entities, and answers future questions from the wiki rather than from fresh web searches. The wiki is a persistent artifact that compounds across sessions, instead of being regenerated each chat.
How is this different from RAG?
RAG retrieves chunks of source documents at query time and feeds them to an LLM as context. The LLM Wiki pattern flips this: an LLM reads sources once, distills them into structured wiki pages, and the wiki itself becomes the retrieval target. The result is faster, cheaper queries, plus cross-references that already exist instead of being inferred at query time. This rebuild adds write-back so the wiki stays current with new sources.
Do I need to know how to code to use this?
No. The implementation is a Claude Code skill that ships as 31 slash commands. You install it once with a shell script, then operate it with commands like /obsidian-save and /obsidian-ingest from any Claude Code session. The vault is plain markdown, so Obsidian works on top of it natively.
Will this break my existing Obsidian vault?
No. The skill never deletes or modifies notes destructively without explicit confirmation. Existing notes are left untouched. New notes follow the AI-First Vault Principle. A health-check command flags pre-AI-first notes so you can update them on your own schedule. Every scheduled agent writes to a daily diff log so you can see what changed overnight and revert if needed.
Does it work without Claude?
The current implementation is built for Claude Code, but the AI-First Vault Principle and the slash-command interface are portable. The vault format is plain markdown with YAML frontmatter, so the underlying knowledge base is model-agnostic. As of 2026-04 the production-tested integration is Claude Code only.
What does it cost to run?
The 26 vault commands work without any API keys: only your Claude Code subscription is required. The 5 research commands require API keys for xAI Grok and Perplexity. Approximate per-call costs as of 2026-04: /x-read around $0.05, /x-pulse around $0.13, /research around $0.04, /research-deep around $0.40 to $0.80, /youtube around $0.04.
Key takeaways
Karpathy’s LLM Wiki pattern is a brilliant foundation. The wiki is the product, chat is the interface, knowledge compounds across sessions.
Append-only ingest fails past a few hundred sources. Stale claims, unresolved contradictions, and missed patterns accumulate invisibly.
The five extensions that turn a Karpathy-style wiki into a working second brain are write-back, reconciliation, unsolicited synthesis, scheduled agents, and AI-first notes.
The AI-First Vault Principle is the most important of the five. Notes designed for AI retrieval beat notes designed for human reading in any vault where the LLM does most of the reading.
Automation has to be reversible. Every scheduled agent in this rebuild writes a diff log and waits 24 hours before any change becomes permanent.
The open-source implementation is live on GitHub and runs as a Claude Code skill with 31 slash commands. Install in two minutes.
If Karpathy’s LLM Wiki is a knowledge base you maintain with an LLM, this rebuild is a knowledge base that maintains itself.
Further reading
Karpathy’s original LLM Wiki gist (2026-02): the canonical pattern.
rohitg00’s LLM Wiki v2 gist (2026-03): adds confidence and supersession.
Penfield Labs on what’s missing from Karpathy’s wiki: typed-link extension.
Andy Matuschak on evergreen notes: the human-first PKM tradition this rebuild departs from.
obsidian-second-brain on GitHub: the open-source implementation.
About the author
Eugeniu Ghelbur is an AI Automation Engineer at Single Grain, where he builds production AI systems for marketing and sales workflows. He ships open-source Claude Code skills and writes about AI knowledge management at ghelburlabs.substack.com. The obsidian-second-brain skill described in this article is live on GitHub at github.com/eugeniughelbur/obsidian-second-brain and has been used in production since 2026-03.
Great article and very interesting skill. I implemented the baseline version of Karpathy’s L zlM Wiki. I’ll give your skills a try.
I’m still experimenting with kb topics. I’d like to use the wiki to cover the internal kb of my business (mktg, sales, support, operations) and use it as a single source of truth to run the business (my context).
Is it a viable approach in your opinion? Today I use a bunch of “satellite md files” within the project. I suppose I may need a custom template for this.
I like the reliability of the daily process you defined.
Appreciate your input 🙏
Really valuable insight here, originality comes from depth of experience and perspective.