

How to Build a Folder-Native AI Agent
AI memory and AI work are both just folders of markdown. Here's how to wire them into one agent.

Google’s Open Knowledge Format gives an agent its memory. A University of Edinburgh paper gives it a workflow. Both are just folders of markdown. Here is how to wire them into one agent you can build this week.
TL;DR
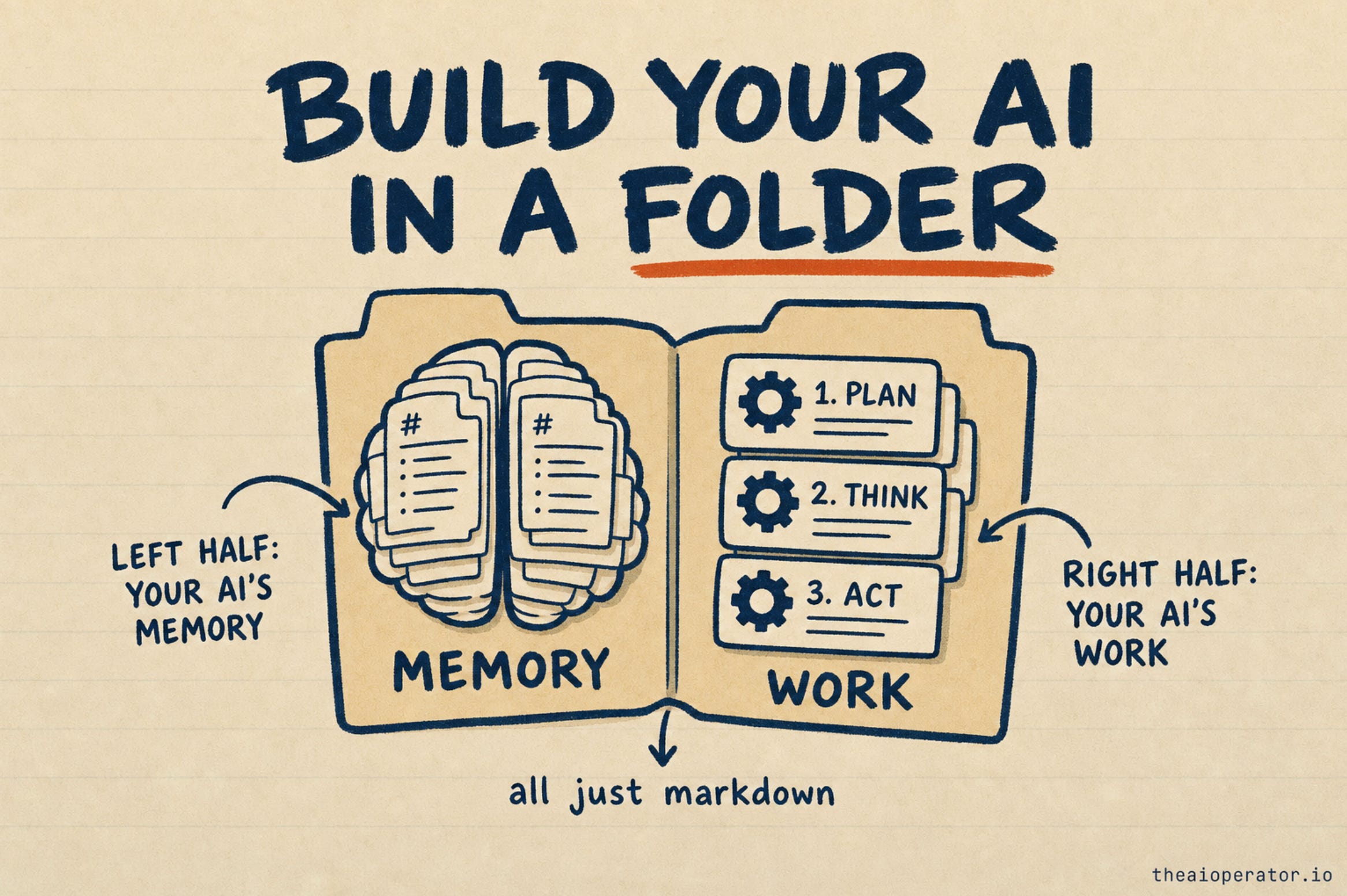
A folder-native AI agent keeps its memory and its work in the same place: folders of plain markdown, in git, with no database and no framework. Google’s Open Knowledge Format (OKF) standardizes the memory half. The University of Edinburgh’s Interpretable Context Methodology (ICM) standardizes the workflow half. Wire them together and you get one agent that reads its own memory, does the work in steps you can check, and writes what it learned back, so it starts smarter every run. This post gives you the exact folder layout, what goes in each file, the loop that makes it compound, and where it breaks.
Two research groups shipped the same idea three months apart, and nobody put the two halves together.
In March 2026, two researchers at the University of Edinburgh published a paper arguing you do not need a multi-agent framework to run an AI workflow. You need numbered folders, each holding a markdown file that tells the agent what to do at that step. The folder structure is the program. Jake Van Clief, who co-authored the ICM paper, has been one of the most consistent public voices explaining how it works.
In June 2026, Google shipped the Open Knowledge Format. Its claim: you do not need a vector database to give an agent its knowledge. You need a folder of markdown files with a little metadata on top, readable by any agent or any human.
One group described how an agent does work. The other described how an agent remembers. Both landed on the same answer: plain markdown, in folders, in git. I wired the two halves into one agent. Here is exactly how it works, and how to build your own.
What “folder-native” actually means
A folder-native AI agent is an agent whose memory and workflow are both ordinary files on disk, not records in a database or steps inside a framework.
That is the whole definition. No special runtime. If you can open a file, you can read its memory. If you can clone a repo, you can ship the whole agent. Three pieces make it work, and you already understand all three:
Markdown is the format. Human-readable text with light structure.
Folders are the organization. Nesting and naming carry meaning the agent can follow.
Git is the spine. Version history, diffs, and rollback come for free.
Everything below is built from those three pieces and nothing else.
The filesystem keeps winning
This is not new, which is exactly why I trust it.
In 1978, Doug McIlroy wrote the rule that made Unix powerful: make each program do one thing well, and let plain text pass between them as the universal interface. Fifty years later, every clever layer we bolted on top has aged worse than the plain-text idea underneath. (the Unix philosophy, McIlroy, Bell Labs)
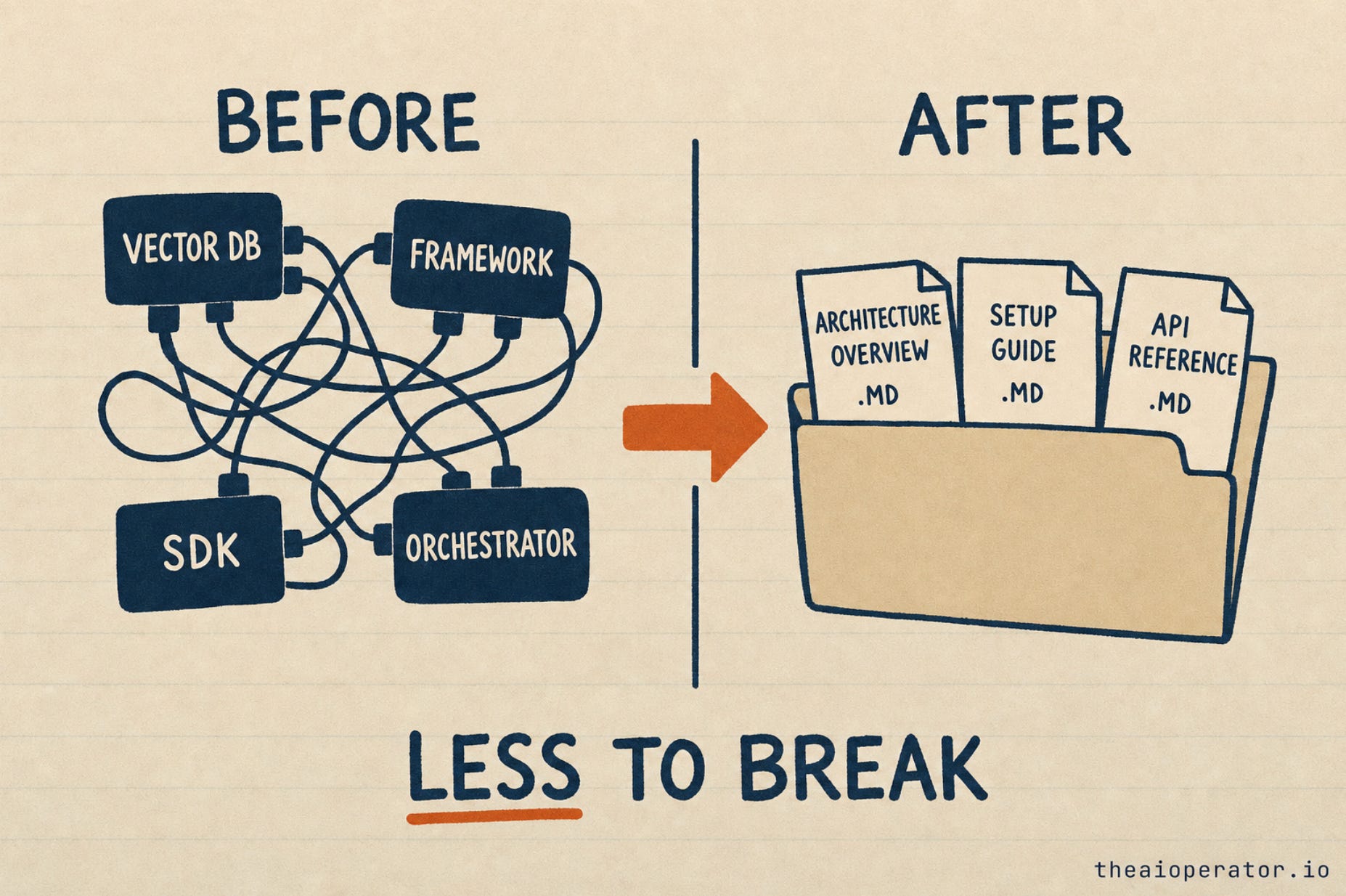
AI is repeating the pattern. We spent two years building scaffolding around language models: vector stores, orchestration frameworks, memory layers with their own SDKs. The quiet result of the last few months is that a folder of markdown beats most of it for the work people actually do.
I wrote about Karpathy’s LLM Wiki when it first went around. The insight: humans abandon wikis because keeping them current is tedious, but a model does not get bored. It will update a cross-reference for the thousandth time without complaint. OKF and ICM are what that insight looks like once it grows into a standard.
Two halves nobody put together
Here is the part worth your attention.
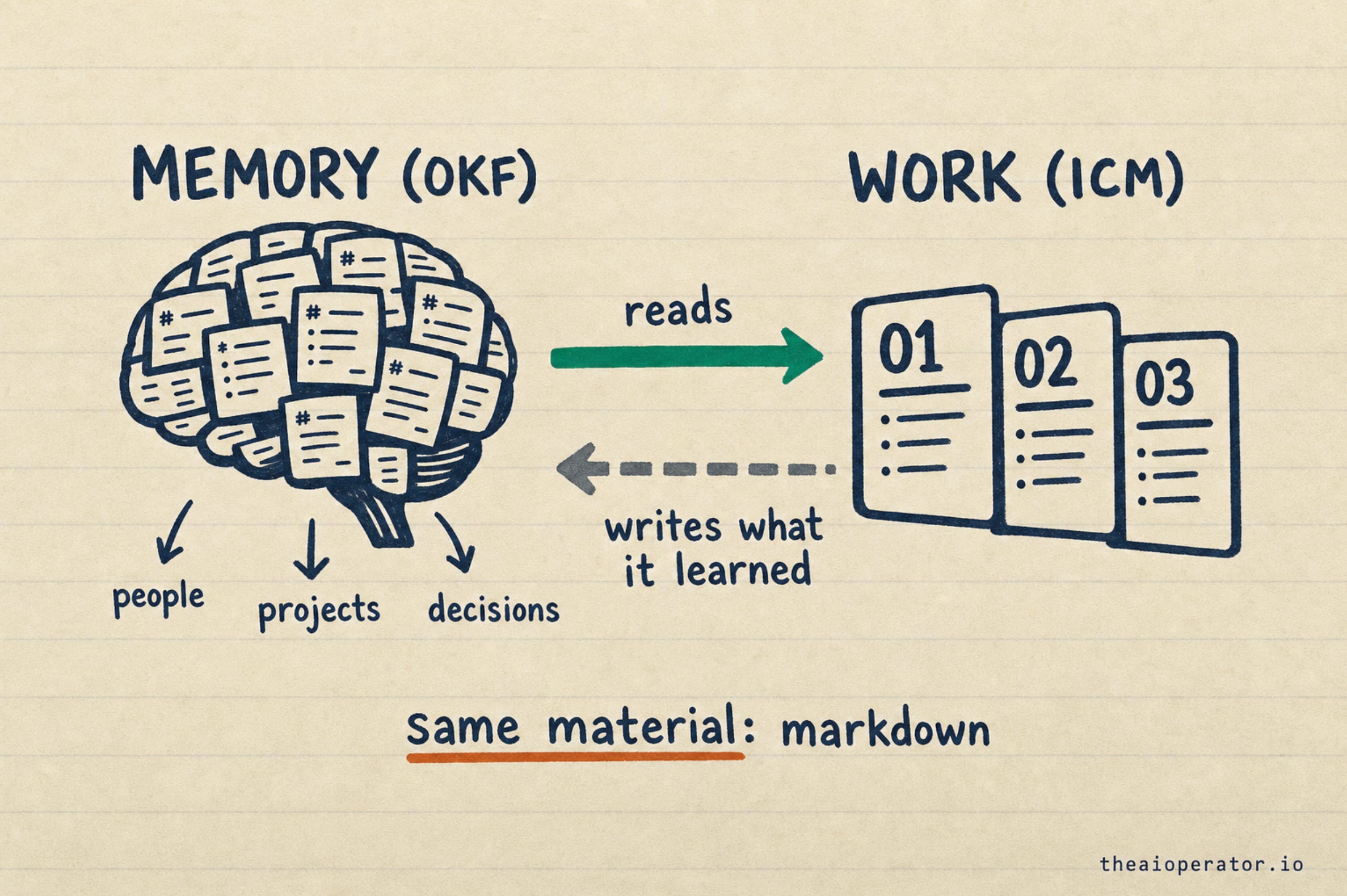
OKF is memory. It is where knowledge lives: facts, context, decisions, people, written as markdown and updated over time. The brain the agent reads from.
ICM is work. It is how a job gets done in stages: research, then draft, then produce, with a human checking the output between steps. The hands.
Every write-up I have seen treats these as separate. They are not. They share the same material, folders of markdown, which means the workflow can read straight from memory and write straight back into it. No glue code. No translation layer. The brain and the hands speak the same language because they are made of the same thing.
What the agent actually looks like
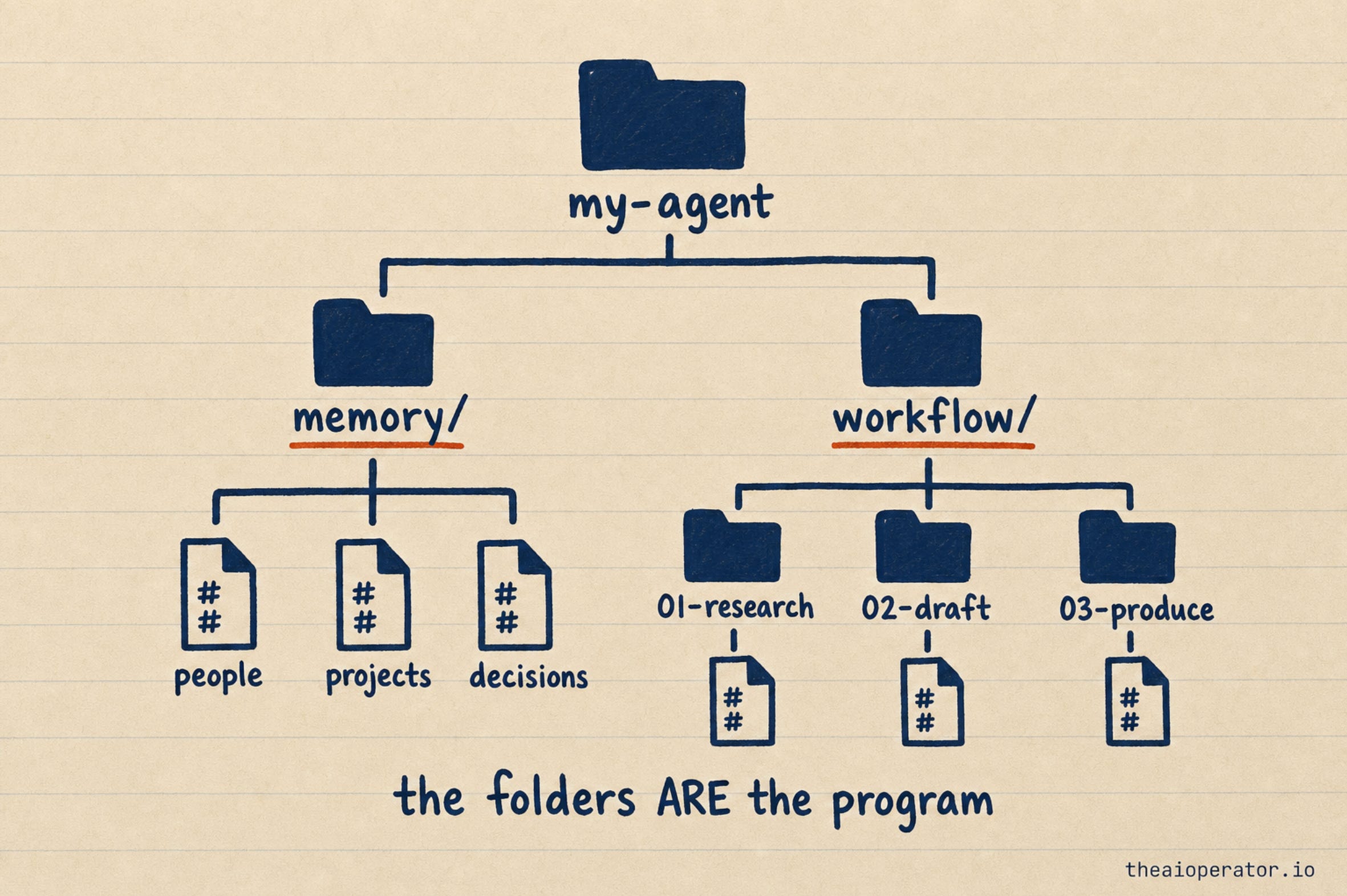
Here is the literal anatomy. One repo, two top-level folders, all markdown.
my-agent/
memory/ <- OKF: what the agent knows
people/
john-smith.md
projects/
weekly-report.md
decisions/
pricing-2026.md
MEMORY.md <- index: one line per note
workflow/ <- ICM: how the agent does a job
01-research/
CONTEXT.md <- instructions for this step
output.md <- what the step produced
02-draft/
CONTEXT.md
output.md
03-produce/
CONTEXT.md
output.md
README.md <- how to run itRead that tree once, and you understand the entire system. memory/ is the brain. workflow/ is the job, broken into numbered steps a human can read in order. There is no hidden state anywhere. The folder structure is the program.
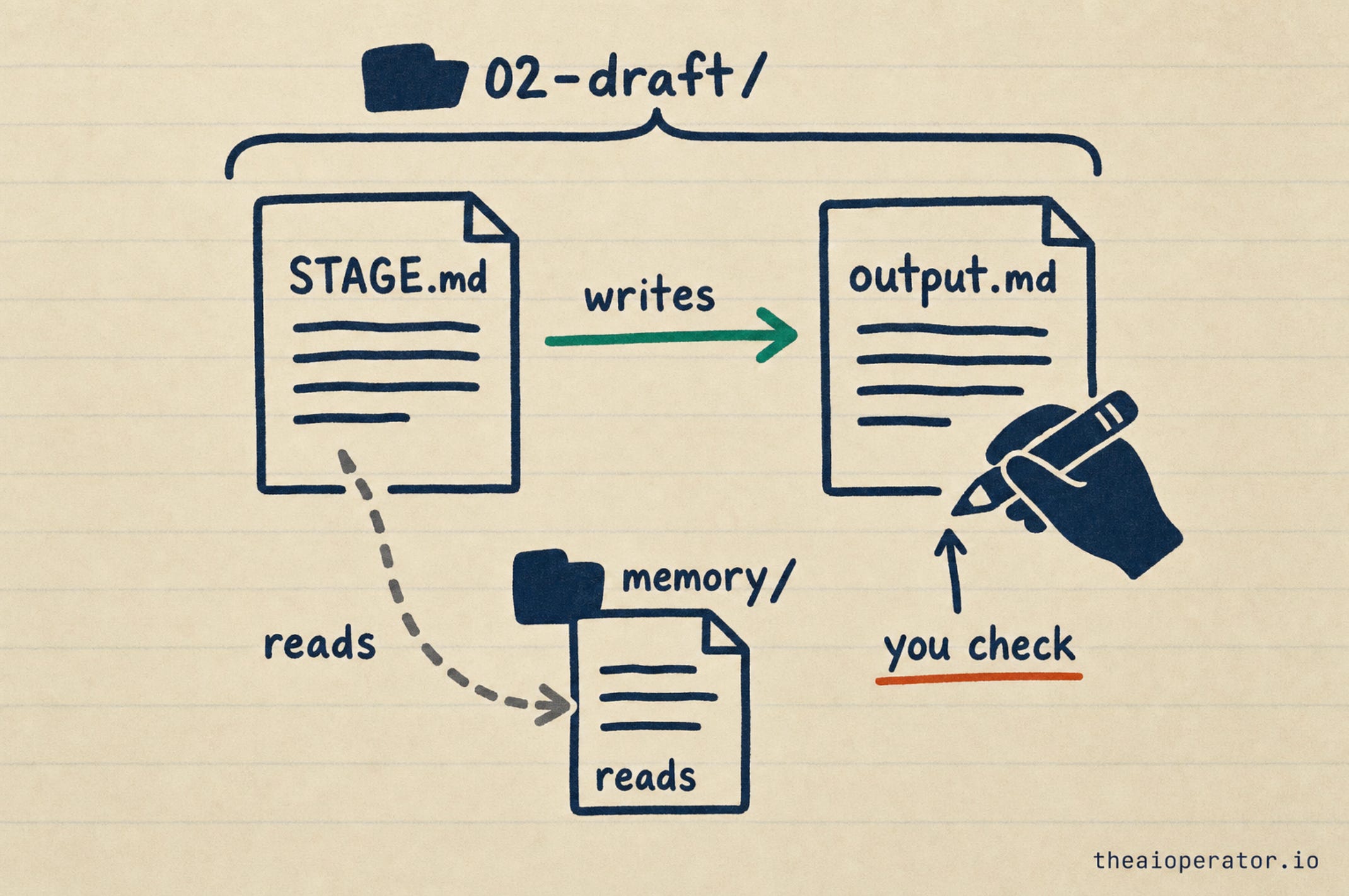
Inside a single stage
Each numbered folder holds two files. A CONTEXT.md that tells the agent what to do (this is the contract file the ICM paper is built around), and an output.md where it writes the result. Here is what a CONTEXT.md looks like:
# Stage 02 - Draft
## Read first
- memory/projects/weekly-report.md
- ../01-research/output.md
## Do
Write a 1-page client report. Use last week's numbersfrom the research step.
Match the client's tone from their note in memory.
## Write to
output.md
## Stop
Wait for the human to approve before stage 03 runs.That is the entire instruction set for one step. Plain English, two file paths to read, one file to write, and an explicit stop. The agent opens CONTEXT.md, pulls exactly the memory it names, does the work, and writes output.md. Then it stops and waits for you.
This is the part frameworks make hard and folders make trivial: every step is a file you can open, read, and correct before the next one runs.
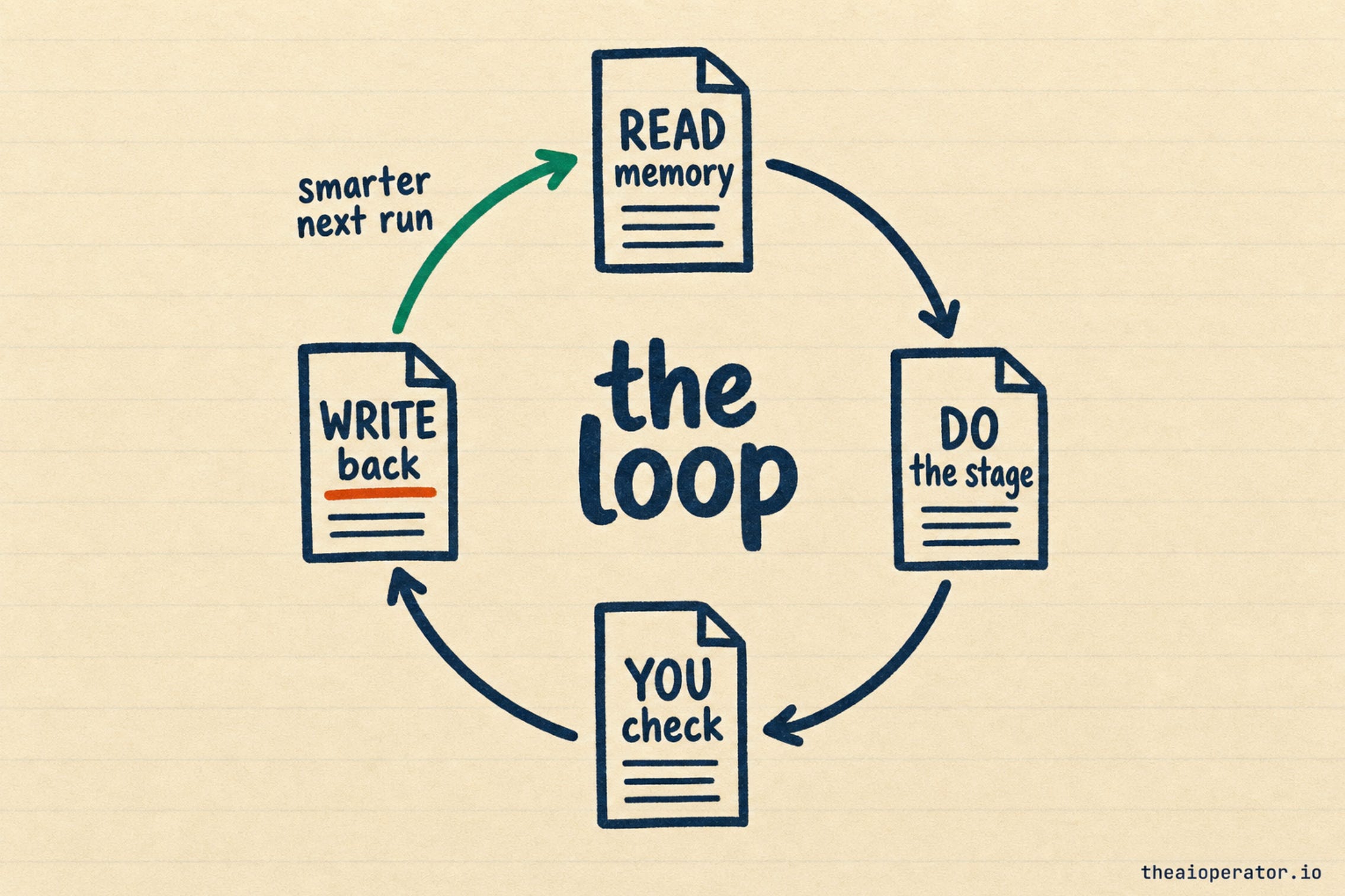
The loop that makes it compound
A pipeline of stages is useful. The loop is what makes it an agent that gets better.
After the work ships, the agent does one more thing: it takes the new facts it learned this run and writes them back into memory/. Next run, it starts from a smarter place, because the work it did became part of what it knows.
The full cycle, all in files:
Read the relevant notes from
memory/.Do the stage, writing
output.md.You check the output and fix it in the file if the angle is off.
Write back the new facts into
memory/.Next run starts from the updated memory.
That is a complete agent. Memory it reads, work it runs, and a loop where the work makes the memory better. All of it plain files you can read on a Tuesday afternoon with nothing open but a text editor.
A worked example: the weekly client report
Concrete beats abstract. Say you want an agent to write your weekly client report.
Stage 01 reads the client’s note from memory/people/, pulls this week’s numbers, and writes a research summary to output.md. You glance at it. If a number is wrong, you fix it in the file.
Stage 02 reads the client’s project note and the research output, then drafts the report into its own output.md. You read the draft. If the angle is off, you correct it right there before anything else runs.
Stage 03 polishes the draft into the final report.
Then the loop closes: the agent writes the new facts it learned this week (a changed priority, a new contact, a decision the client made) back into memory/people/ and memory/decisions/. Next Monday, the agent starts from a smarter place. You did not retrain anything. You did not migrate a database. You edited text files.
Why this beats the stack you were about to build
Three reasons, and none are about benchmarks.
You can see everything. No hidden state, no opaque vector index, no “trust me” black box. Every intermediate step is a file. When the output is wrong, you open the folder and find where it went wrong. The system is inspectable by default, not because someone bolted on a logging dashboard.
You can change anything. A non-technical person can edit a markdown file. The person who owns the work can correct the agent without calling a developer. The control surface is a text editor.
It outlives the model. Your knowledge and workflows are not trapped inside a product. They are files in a folder in git. When the next model drops, you point it at the same folder. Nothing to migrate, nothing to rebuild. I have watched three model generations come and go while my own setup kept running on the same files.
How to build your own this week
You do not need either standard to start. You need a folder. Here is the smallest version that works:
Make two folders:
memory/andworkflow/. Put them in a git repo.Seed memory. Drop in a handful of markdown notes about the things your agent needs to know. One fact per file. Add a
MEMORY.mdIndex with one line per note.Write one stage. Create
workflow/01-do-the-thing/CONTEXT.mdwith three sections: what to read, what to do, what to write. Point an agent (Claude Code, or any tool that can read and write files) at it.Run it and read the output. Fix the output file by hand if it is off. This is the human-in-the-loop, and it is the point, not a workaround.
Close the loop. Add a final instruction: write any new facts back into
memory/. Run it again next week and watch it start smarter.Add stages only when a single one gets crowded. Split
01into01-researchand02-draftWhen the instructions stop fitting on one screen.
Add the heavy machinery (a database, a framework) only when a folder genuinely cannot do the job. That moment is later and rarer than you think.
Where this breaks
I am not going to tell you that folders solve everything, because they do not.
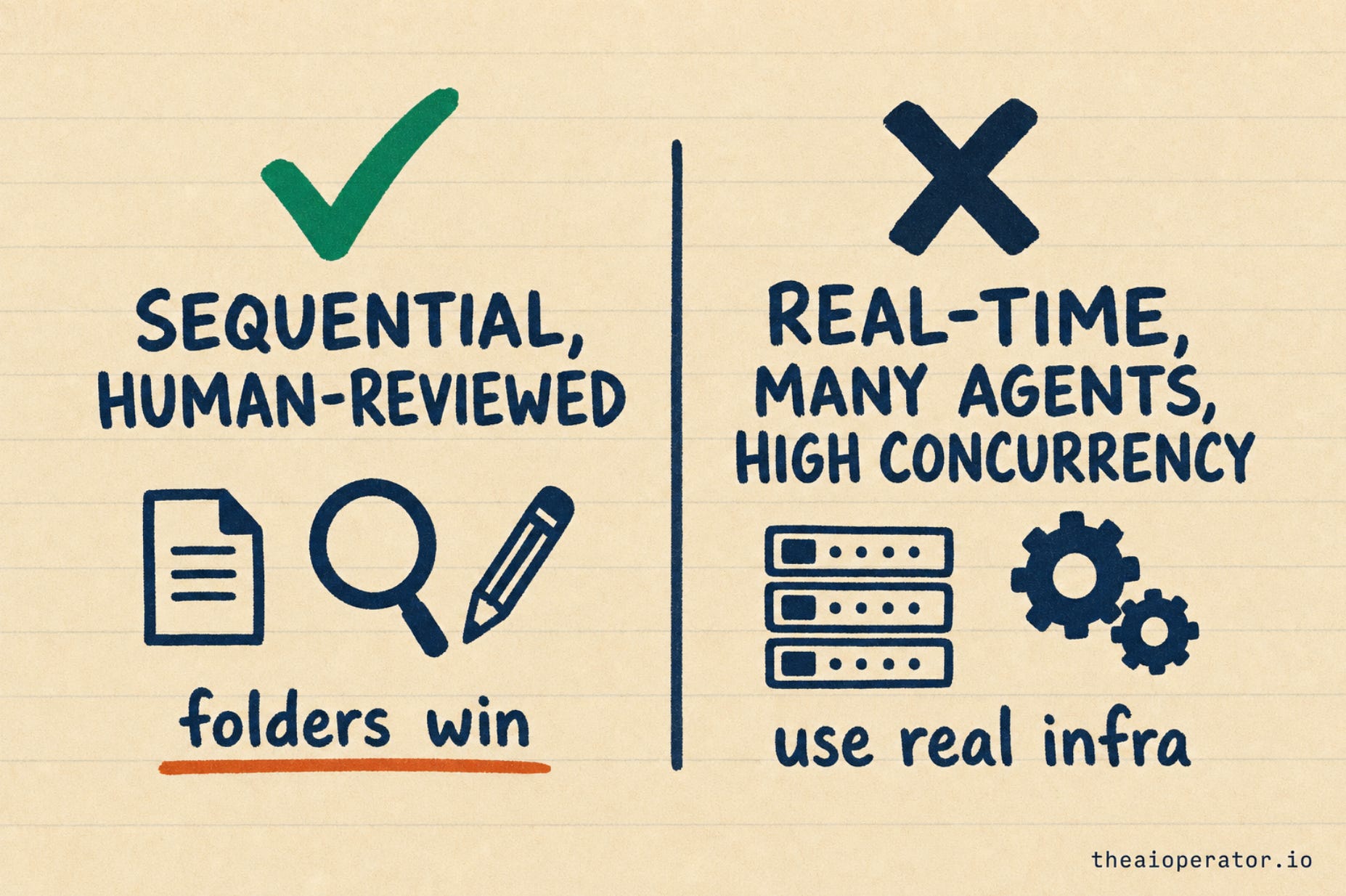
The Edinburgh paper is honest about this, and so am I. This pattern fits sequential work that a human reviews. It is not built for real-time, many-agents-talking-at-once systems, or high-concurrency services where you need queues and proper infrastructure. For that, the frameworks earn their complexity.
Both standards are also early. OKF is a version 0.1 from a single company. ICM is a young methodology with a small community. This is the start of something, not a settled stack. I am betting on the direction, not claiming the destination.
But for the large, boring middle, the reports and the research and the content and the knowledge work most of us spend our days on, the folder wins. It is simpler than the problem we built frameworks to solve.
I am not theorizing
I maintain an open-source second brain that has been cloned and starred by over 3,000 developers. It is folders of markdown, maintained by AI, on the exact pattern OKF describes. The code is public: github.com/eugeniughelbur/obsidian-second-brain.
This week I made it speak the standard directly. It now exports a valid OKF bundle, so the vault any of those developers run is portable to anything that reads the format. I also run a capture pipeline that takes a voice note or a photo from my phone and files it into the right note, plus a step that means the agent never leaves a dead link: when it references a person or project that has no note yet, it creates that note and fills it.
None of that is a demo. It is what I use every day. The point is not the specific tool. The point is that the architecture works, you can see it working, and you can build it yourself, because it is just files.
Start with a folder
If you take one thing from this: stop reaching for a database or a framework as the first move. Start with a folder of markdown. Let the agent read it, work in it, and keep it current.
The filesystem won the first time, in 1978. It is winning again, for the same reason: plain text outlasts the scaffolding built on top of it. The only question is whether you start now or after everyone else has.
Frequently asked questions
What is a folder-native AI agent?
A folder-native AI agent is an AI agent whose memory and workflow are both stored as plain markdown files in folders, versioned in git, with no database and no orchestration framework. The agent reads its memory from files, does work in numbered stage folders, and writes new facts back to memory.
What is the Open Knowledge Format (OKF)?
OKF is a standard from Google Cloud, released in June 2026, for packaging knowledge as a folder of markdown files with simple metadata, so AI agents can read and maintain it without a database or scraping. It defines the memory layer of a folder-native agent.
What is Interpretable Context Methodology (ICM)?
ICM is a method from a 2026 University of Edinburgh paper for running multi-step AI workflows using numbered folders and markdown instead of a coding framework. One agent reads the right file at each stage, and a human reviews the output between stages. It defines the workflow layer.
How are OKF and ICM related?
They are the same idea applied to two halves of one agent. OKF is the memory (what the agent knows). ICM is the workflow (how the agent does work). Because both are folders of markdown, you can wire them together so a workflow reads from memory and writes back to it.
Do I need a vector database for AI memory?
For a lot of everyday knowledge work, no. A folder of markdown the model reads directly avoids the “lost in the middle” problem of stuffing everything into one prompt (Liu et al., 2023), and it is far simpler to inspect and edit. Databases earn their place at scale, not by default.
Is folder-native AI ready for production?
For sequential, human-reviewed workflows, yes, people run it today. For real-time, high-concurrency, or many-agent systems, no, you still want proper infrastructure. Both OKF and ICM are early, so treat this as a direction to build toward, not a finished standard.
Can I use this with my existing Obsidian vault?
Yes. An Obsidian vault is already folders of markdown, which is most of the way to OKF. That is why the pattern is spreading fast among people who already keep notes this way.
Key takeaways
A folder-native AI agent keeps memory and work as plain markdown in folders, in git, with no database and no framework.
Two 2026 standards landed on the same answer independently: Google’s OKF for the memory layer, the Edinburgh ICM paper for the workflow layer.
Wire them together and a workflow reads from memory and writes back to it, so each run makes the agent’s memory smarter.
The build is simple: two folders (
memory/andworkflow/), one markdown note per fact, oneCONTEXT.mdper step, a human check between steps, and a loop that writes new facts back.The real advantages are inspectability, editability by non-developers, and surviving the next model with zero migration. Not speed.
Folders are not for everything. Real-time and high-concurrency systems still need real infrastructure. This fits the large, sequential, human-reviewed middle.
Further reading
Google Cloud, How the Open Knowledge Format can improve data sharing (the OKF v0.1 announcement, June 2026).
Van Clief & McDermott, Interpretable Context Methodology: Folder Structure as Agentic Architecture (University of Edinburgh, arXiv:2603.16021, March 2026).
The ICM reference implementation on GitHub: github.com/RinDig/Interpreted-Context-Methdology.
Jake Van Clief on ICM (co-authored the paper and posts regularly about the methodology publicly).
Andrej Karpathy’s LLM Wiki gist (the origin of the “agents do not get bored maintaining a wiki” insight).
Liu et al., Lost in the Middle: How Language Models Use Long Contexts (why folders the model reads directly beat one giant prompt).
I rebuilt Karpathy’s LLM Wiki. Here’s what’s missing from the original.
The obsidian-second-brain skill on GitHub: github.com/eugeniughelbur/obsidian-second-brain
About the author
Eugeniu Ghelbur is an AI Automation Engineer at Single Grain, where he builds production AI systems for marketing and sales workflows. He ships open-source Claude Code skills and writes about AI knowledge management at theaioperator.io. The obsidian-second-brain skill described here is live on GitHub at github.com/eugeniughelbur/obsidian-second-brain, where over 3,000 developers have starred it.
Wow! This one is going straight to my favorites.
I teach AI to business people through Claude Cowork. My Work OS is ~80% of what you describe:
1. Each project had a Workflows/ folder with WF-01, WF-02, etc => maps out biz processes for that domain, f.i Sales, Marketing, Clients
2. Skills are my autonomous agents
3. My memory is in kb.md topic files; either Knowledge/ inside the workspace or _Knowledge/ outside for global knowledge, f.i. Naming conventions global vs client data local
4. Skills generate files in Outputs/ => weekly of periodic sweep across workspace to decide if new knowledge should be added to the kb.
Many challenges I won’t mention here.
If interested, I’d love to connect and have a show&tell session. It feels like we could benefit from it. DM me!
PS: can you share the official research papers?