

I built the primitive. Glean is the wrong wedge.
Glean is a $7.2B bet you can search your way out of a messy corpus. I think the wedge is the opposite. Here is the primitive I shipped.


TL;DR
Glean is a $7.2B bet that you can search your way out of a messy corpus.
I think the wedge is the opposite: refuse bad notes at write-time.
I have shipped the primitive at one-person scale in OSB v0.7. The company version is still a thesis.
New here? I write one post per Tuesday on AI workflows, agent patterns, and what actually works in production. Subscribe to The AI Operator →
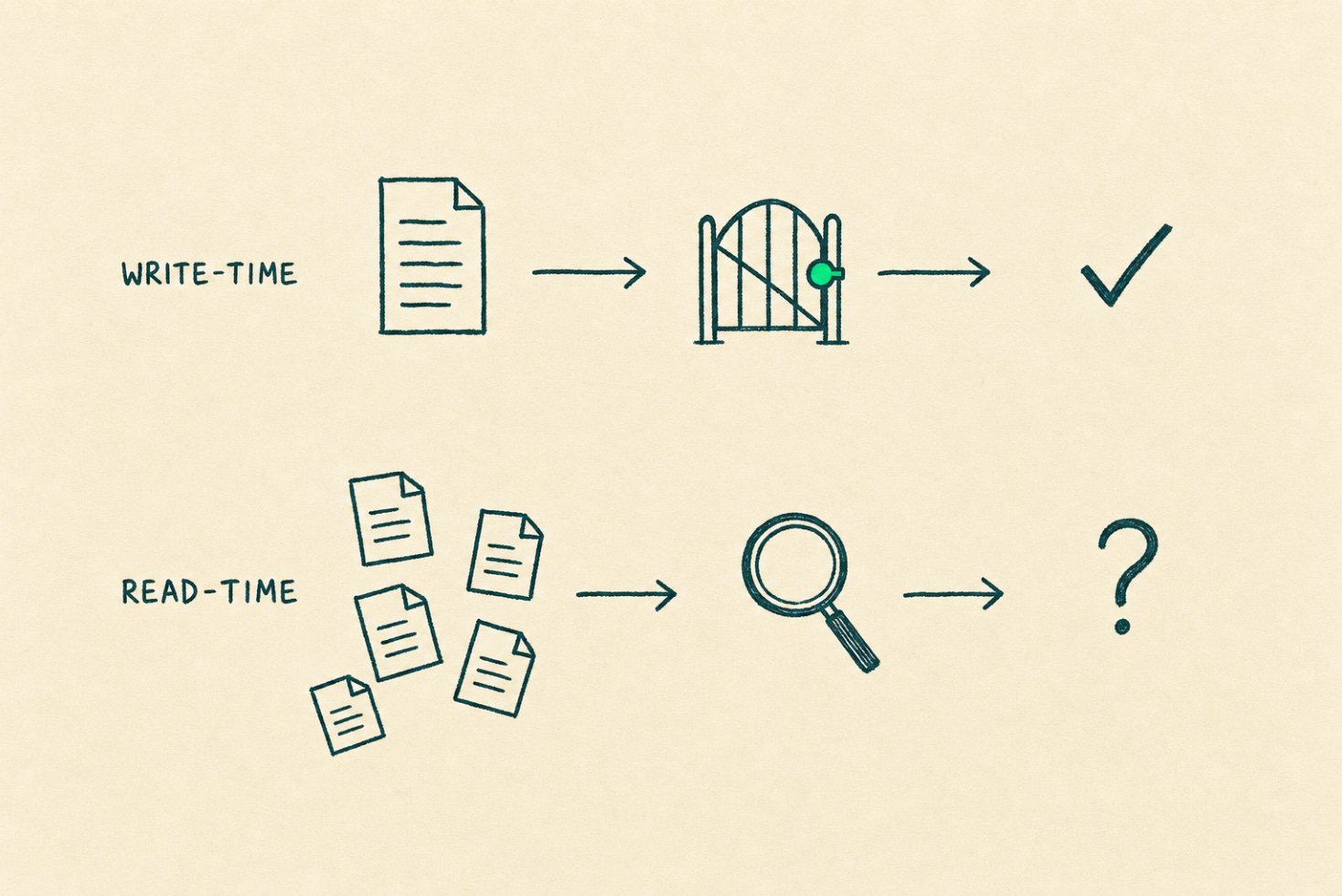
The wedge is write-time, not read-time
The way to beat Glean is to clean before you save, not search after. Glean is a $7.2B work-AI platform (Series F, June 2025, $200M ARR per Futurum 2025-09). It crawls Slack, Notion, Google Drive, Jira, builds a permissions-aware knowledge graph, and runs read-time search plus agentic actions across the pile. The pile stays a pile.
I think the better wedge is intercepting content at write-time. Before a note saves, an agent checks whether it has the metadata, the preamble, and the structure that make it findable later. If it does not, the note gets flagged at the door.
The logic is simple. If you clean on write, you do not need a seven-figure search layer to find things on read.
I want to be honest about scope up front. The validator hook runs against my personal vault, not a company corpus. But this is not pure theory either. Since shipping the primitive, a venture-backed founder who found me through the open-source repo became a paying consulting client, and over a recent in-person session signaled willingness to back the team version if I build it. The rest of this post is what that team version would look like. Public version of the pitch.
What “second brain for companies” would actually mean
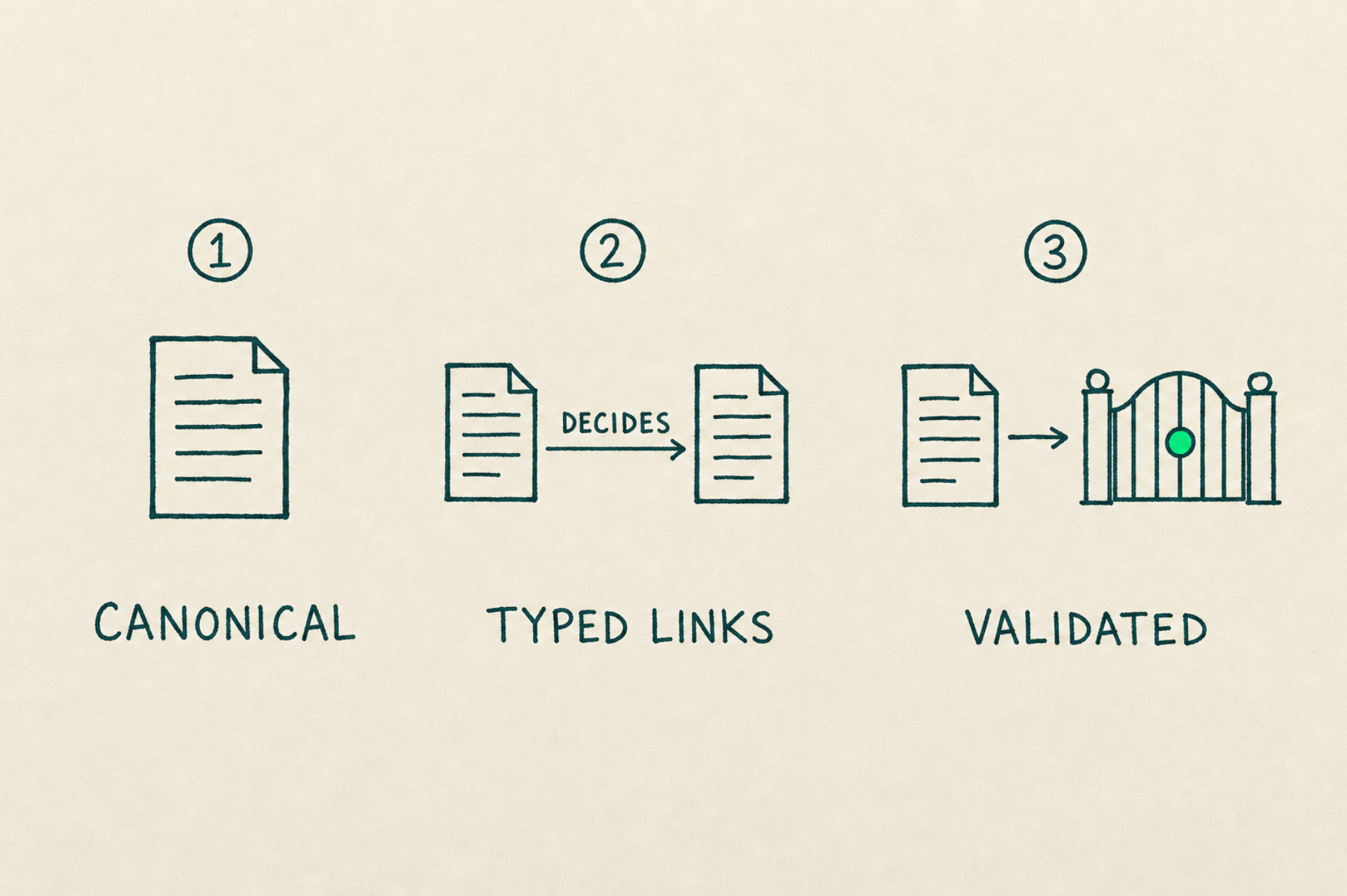
A company second brain is a single graph where every document has one canonical home, typed links, and machine-readable metadata. Three properties define it:
One canonical doc per concept. Duplicates get merged or redirected.
Typed backlinks. Not just “this links to that,” but “this DECIDES that” or “this BLOCKS that.”
Write-time validation. An agent reviews the note before it persists.
Glean does none of this. Glean is a flashlight in a warehouse. The thesis is to build the warehouse.
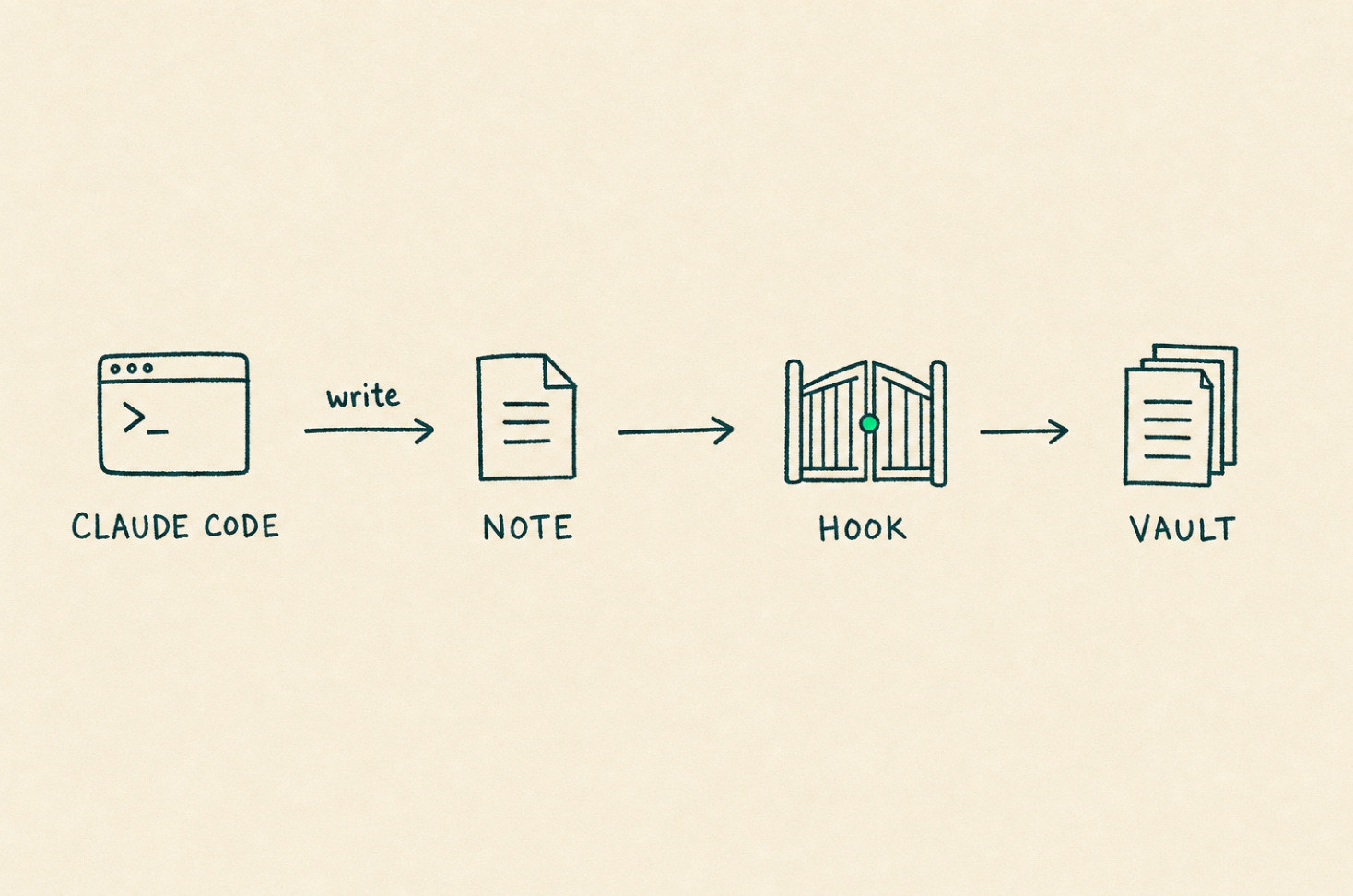
The primitive I have actually shipped
The primitive exists today as a Claude Code PostToolUse hook that enforces a write-time schema on every save. In OSB v0.7, I shipped it at hooks/validate-ai-first.sh. It runs every time Claude Code writes a file inside my vault path. The hook warns when a note violates the AI-first rule: missing frontmatter, missing preamble, missing ai-first: true, or otherwise failing the schema I have set for my own corpus.
This is a one-person primitive. It runs against my vault. It is not multiplayer, it has no duplicate detection across a team, and it has no notion of canonical ownership across humans. What it does prove is that the agent surface (Claude Code) plus the substrate (Obsidian, plain markdown, local files) can enforce a write-time schema without a separate server, a separate UI, or a separate buyer.
The repo is public at github.com/eugeniughelbur/obsidian-second-brain, MIT licensed, around 1.3K stars, 33 commands as of v0.8.0. (on May 19th, 2026).
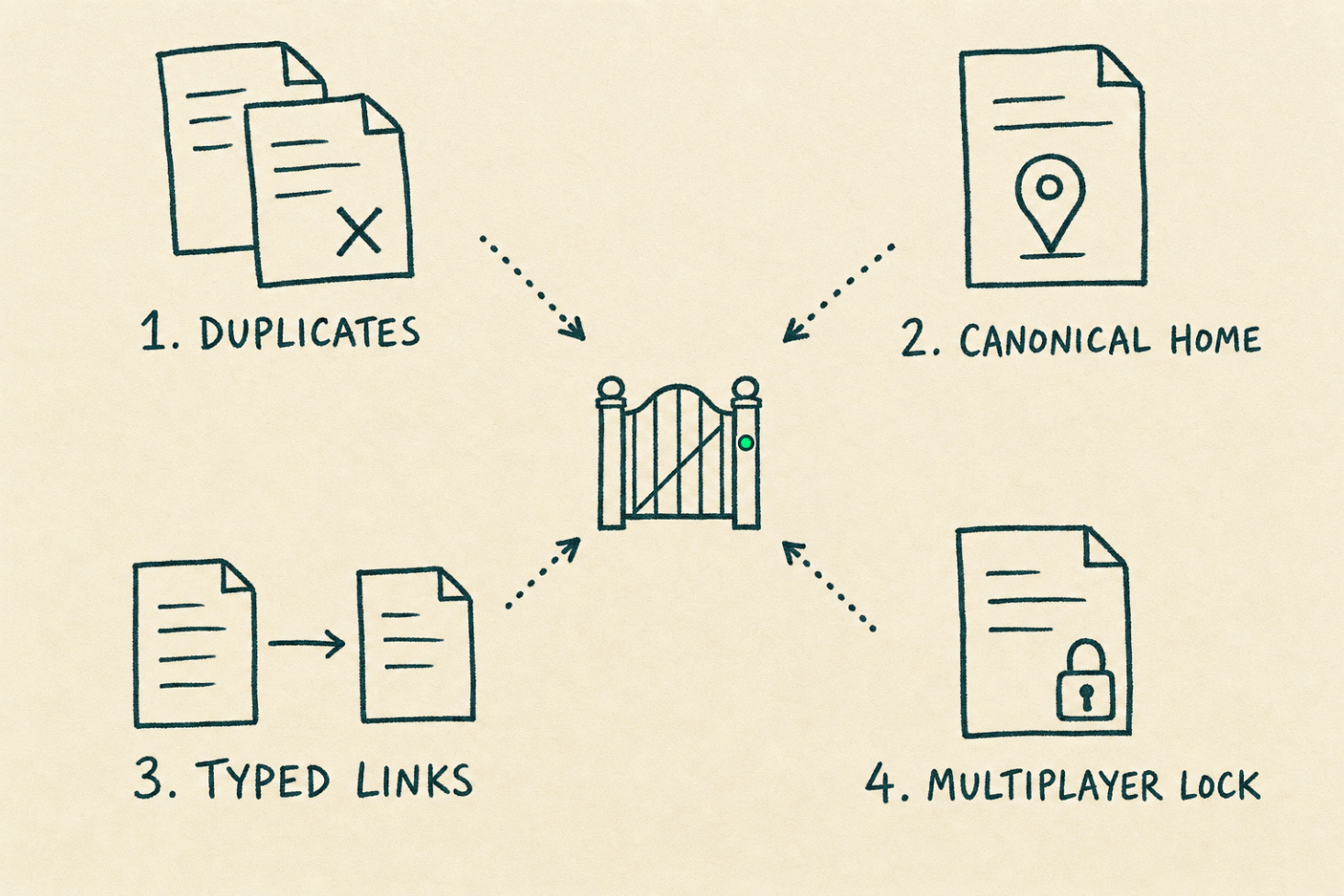
What the company version would need
The personal hook is the architecture in miniature. To make it work for a team, four things have to be added:
Duplicate detection across a shared vault, not just schema checks on a single file.
Canonical-location suggestion when two docs claim the same concept.
Typed links (decides, blocks, supersedes, references) instead of bare wikilinks.
A multiplayer lock model so two people are not silently editing the same canonical doc.
The schema I would push for, carried in every doc’s frontmatter:
type: decision, spec, retro, meeting, reference, draftowner: single human, not a teamstatus: draft, active, archived, superseded-bylinks_in/links_out: typed (decides, blocks, supersedes, references)canonical_for: the concept this doc ownslast_validated: ISO date
The agent rejects anything missing these. That sounds harsh. In practice the agent can fill most fields itself and ask one question. The cost of being strict at write-time is a short prompt. The cost of being loose is a six-month archaeological dig later.
Why Glean cannot pivot here
Glean cannot pivot here because write-time validation is a developer-tools sale, not an IT sale. Glean’s distribution is enterprise IT. Their buyer wants a layer over the existing mess because changing the mess is a political fight. Write-time validation requires changing how people write, which means changing the tool they write in.
That is a developer-tools sale, not an IT sale. Different buyer, different motion, different product surface. Glean does ship agentic write actions (Agentic Engine 2, Canvas co-authoring, Glean Protect Plus governance), but those are AI-agents-execute-tasks-in-source-systems, not validate-the-document-against-a-schema-before-it-saves. The wedge I want is at the editor, in the human’s write path, before the doc exists. The wedge has to start bottom-up, inside the writing tool, not top-down from a CIO budget line. That is why I built the open-source repo at github.com/eugeniughelbur/obsidian-second-brain instead of pitching a platform.
How does this connect to the personal second brain
I have written about the personal version of this pattern in three places worth reading:
I rebuilt Karpathy’s LLM wiki in Obsidian. The same canonical-doc-per-concept rule, scaled down to one person.
I built a tool that lets my Obsidian vault talk back. The agent loop that the validator hook grew out of.
I built this for myself, then 1,374 people cloned it. The signal that solo patterns find an audience.
The company version is not a new architecture. It is the personal vault pattern with multiplayer locks and a stricter schema.
Why this is the right wedge in 2026
Write-time cleanup became the right wedge in 2026 because three forces converged, and one third-party analyst already raised doubts about whether Glean’s knowledge-graph moat survives. Futurum Group wrote in September 2025 that Glean’s “future success depends on whether its knowledge graph depth can hold off an improving and natively integrated Microsoft 365 Copilot.” That is the moat question every founder should be asking about every search-layer business: what happens when the suite vendors index the same corpus natively. Three forces converged this year:
Long context windows at production cost. Write-time validation against a meaningful slice of the corpus is finally cheap enough to run on every save.
Glean’s $7.2B valuation made every PM realize search is the consolation prize for a clean corpus. The category is funded, which means the category is also legible to founders looking for the inverse bet.
Agent surfaces inside editors are now real. Claude Code, Cursor, and the Obsidian plugin ecosystem mean an agent can sit in the write path without a custom client.
The opening is write-time cleanup as a layer that lives inside the editor, not a search box bolted on top.
Frequently asked questions
Is this a Glean competitor today?
No. Glean is a shipped product, $200M ARR by mid-2025, customers in 27 countries, $1M+ contracts growing 3x year over year (Futurum, 2025-09). I have a personal primitive and a thesis. The argument is about where the category is going, not where it is.
Does write-time AI cleanup slow people down?
It adds friction at save. The bet is that the friction is small relative to the time later spent hunting for the right version of a doc that should not have existed in the first place. I have not measured this at team scale.
Why Obsidian as the substrate?
Plain markdown, local files, plugin API, git-native. No other tool I have tried gives me a writable graph with a real agent surface I can hook into. The repo is at github.com/eugeniughelbur/obsidian-second-brain.
What is the proof you have right now?
A working PostToolUse hook in OSB v0.7 that enforces the AI-first schema against my personal vault. It runs on every Claude Code write inside the vault path. That is one-person proof of architecture. The business proof so far is one inbound founder, paid consulting client, in-person investor signal. Early. Not a term sheet. Enough to know the wedge is real to someone who runs a real company.
What would change your mind about the wedge?
If a team adopted write-time validation and the corpus did not get measurably cleaner, the thesis is wrong. The honest next step is to run that test, not to claim I already have.
So what
If you are choosing a knowledge tool in 2026, the question is not “which search is best.” The question is “what stops bad docs from being written in the first place.” Search is the tax you pay for skipping that question. The second brain for companies is the answer that skips the tax. I have the personal primitive. The company version is still a thesis, and I would rather say so than fake the receipts.
If you got value from this post:
Free: I publish one of these every Tuesday on AI workflows, agent patterns, and what actually ships. Subscribe to The AI Operator →
Paid ($8/mo or $80/yr): Monthly deep-dives with the actual code, configs, and setup walkthroughs behind the thesis posts. Coming up in a few weeks: the
hooks/validate-ai-first.shwalkthrough, exact frontmatter schema, Claude Code PostToolUse config, and the prompt templates that catch what a regex cannot. Upgrade to paid →Repo: github.com/eugeniughelbur/obsidian-second-brain. The open-source primitive this post is built on. MIT licensed, 33 commands as of v0.8.0.
Find me on X: @eugeniu_ghelbur. Replies open.