

Karpathy's LLM Wiki v2: What to Keep, What to Skip
I rebuilt it, ran it daily for months, and most of the v2 hype is overkill.


The internet has spent two months designing a “v2” of Andrej Karpathy’s LLM Wiki: confidence scores, supersession chains, forgetting curves, vector search, lifecycle hooks.
I rebuilt the original and have run it every day for months across a repo that 2,317 people have now starred.
Here is the honest report on which v2 ideas earn their place, and which are overkill you will rip out in a week.
Andrej Karpathy posted a gist last year describing how he keeps an LLM-maintained wiki: raw sources go in untouched, the AI owns a folder of markdown notes, and a rules file tells it how to ingest, update, and query. I rebuilt that pattern as a working system and wrote about what the original left out.
Since then a small genre has appeared. People are publishing “LLM Wiki v2” gists. The most-shared one (by a developer who goes by rohitg00) adds confidence scoring, supersession chains, forgetting curves, hybrid vector search, and event hooks. Other versions pile on audit trails, tiered memory, and quality scores.
It reads like a real upgrade. Most of it is not.
I am not theorizing. I have run my rebuilt wiki every day for months, and I open-sourced the whole thing as obsidian-second-brain. So here is the difference between the v2 ideas that survive contact with daily use and the ones that look smart in a gist and die in practice.
First, the part everyone gets right
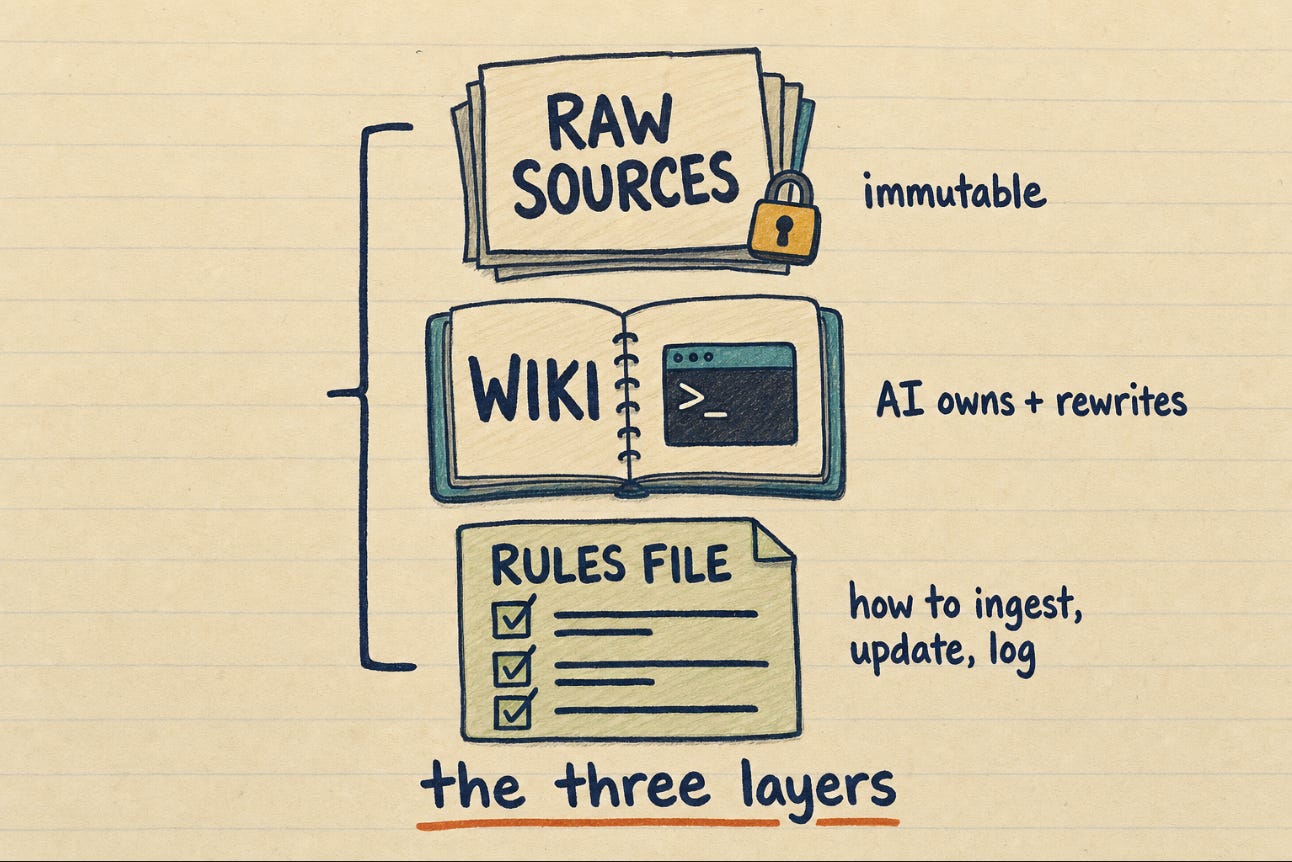
If you landed here cold, the pattern is three layers, and it genuinely works.
One: raw sources, immutable. Whatever you feed it (an article, a transcript, a meeting) lands in a folder and never gets edited. That is your ground truth.
Two: the wiki. A folder of markdown notes the AI owns and rewrites. New information does not get appended to the bottom. It gets folded into the existing note, and contradictions get reconciled.
Three: the rules file. One markdown file that tells the AI how to ingest a source, how to update a page, how to record what it did. An index.md for navigation and an append-only log.md for history.
The reason it beats dumping everything into a giant context window: a curated wiki of 50,000 to 100,000 tokens answers most questions without loading your entire corpus. You spend tokens on the answer, not on the haystack. That part is real and v2 does not change it.
What “v2” actually means right now
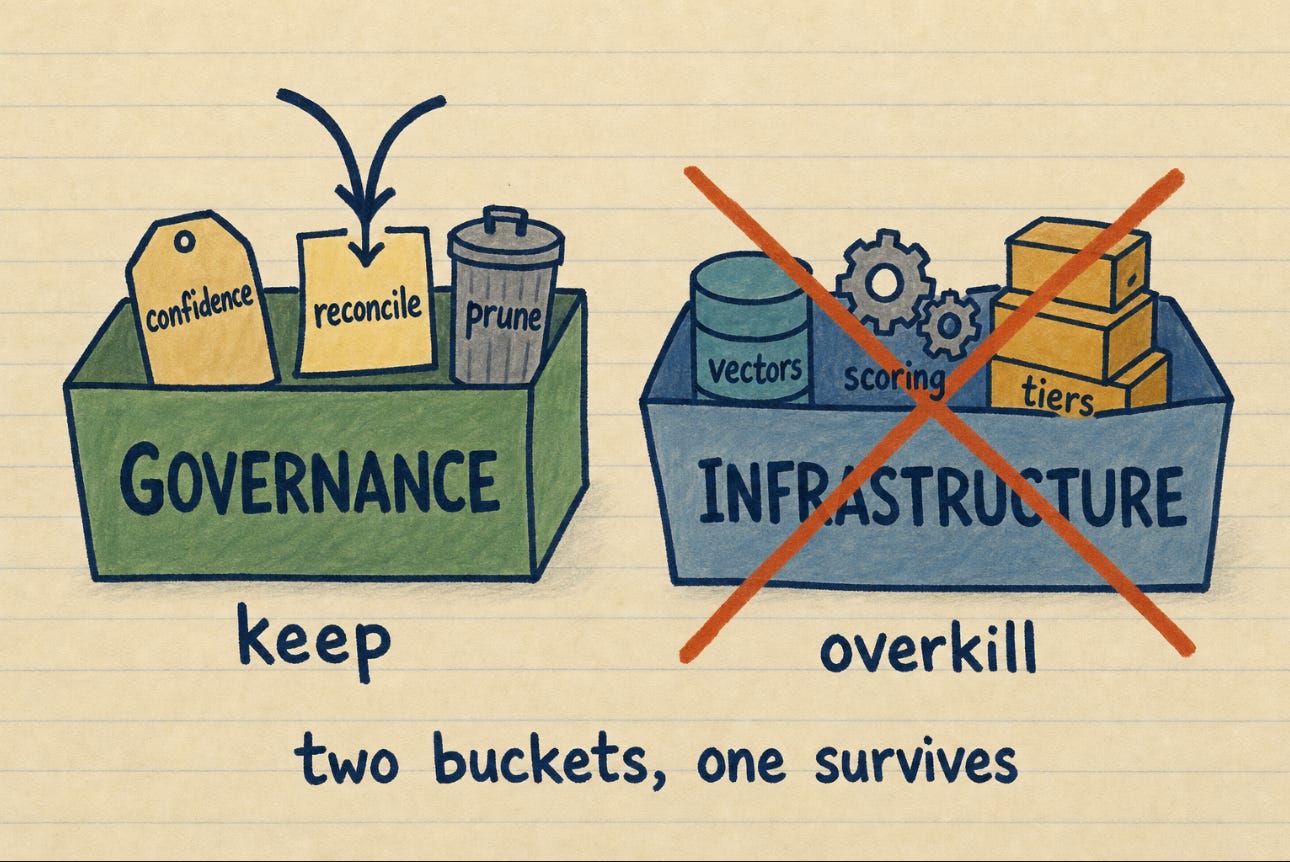
There is no official v2. Karpathy’s gist is still the only canonical spec. “v2” is a community label for a pile of proposed additions, and they cluster into two buckets.
Governance features: confidence scores on claims, supersession chains so an old fact points to the new one that replaced it, and “forgetting curves” so stale notes decay instead of rotting in place.
Retrieval and infrastructure: hybrid search (keyword plus vector embeddings), lifecycle and event hooks, quality scoring, tiered memory.
The first bucket is about whether the wiki tells you the truth. The second is about machinery. After months of running this, the split between them is exactly the split between what works and what is overkill.
The v2 ideas I shipped and kept
The governance bucket earns its place. Every one of these is in the system I run.
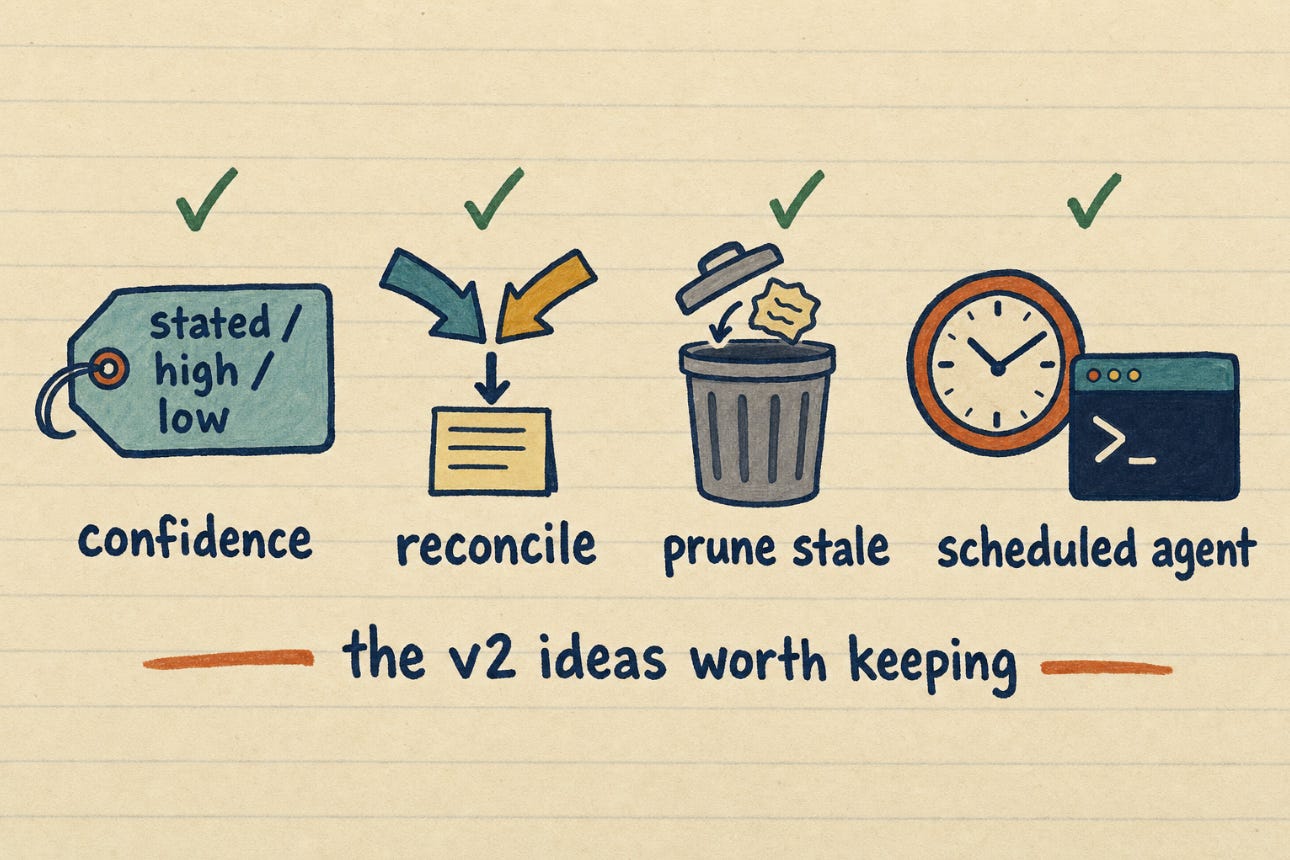
Confidence markers. Every claim my wiki writes carries a tag: stated, high, or low. It costs almost nothing (one word per fact) and it changes how you read. When the AI synthesizes across notes, a stated claim gets treated as a quote, not a truth. This is the single highest-value v2 idea and it requires zero infrastructure.
Supersession, done as reconciliation. When a new source contradicts an existing note, the wiki does not keep both and shrug. A command reconciles them: the note gets rewritten to the current truth, and the change is logged. You do not need a formal “supersession chain” data structure. You need the AI to actually resolve the conflict instead of hoarding it.
A forgetting curve, but boring. The fancy version tracks decay scores and timestamps. Mine is simpler: lessons get reviewed, and the ones that stopped being true get pruned. Notes that just accumulate become a graveyard. The point of a forgetting curve is not the math. It is that something deletes.
Lifecycle hooks, as scheduled agents. This one is real and I run it. Background agents wake up on a schedule and maintain the wiki while I am not looking: reconcile contradictions, synthesize patterns, flag stale claims. You do not need an event-bus abstraction. You need cron and a rules file.

The v2 idea I skipped, and why
Hybrid vector search is the headline feature of almost every v2 gist. I tried it. I took it out.
Here is the thing nobody writing these gists seems to have measured: at wiki scale, you do not have a retrieval problem. A curated wiki is 50,000 to 100,000 tokens. That is small. Grep plus read finds the right note faster and more predictably than an embedding lookup, with no vector database to host, no index to keep fresh, and no “why did it return that chunk” debugging.
Vector search earns its keep at hundreds of thousands of documents. A personal or team wiki is not that. Bolting embeddings onto a 200-note vault is solving a problem you do not have, and paying for a database to do it.
The same goes for tiered memory and elaborate quality-scoring engines. They are answers to scale problems. At the scale where an LLM wiki is actually useful, they are weight.
What is genuinely still missing
Honesty cuts both ways, so here is the gap the v2 gists also miss.
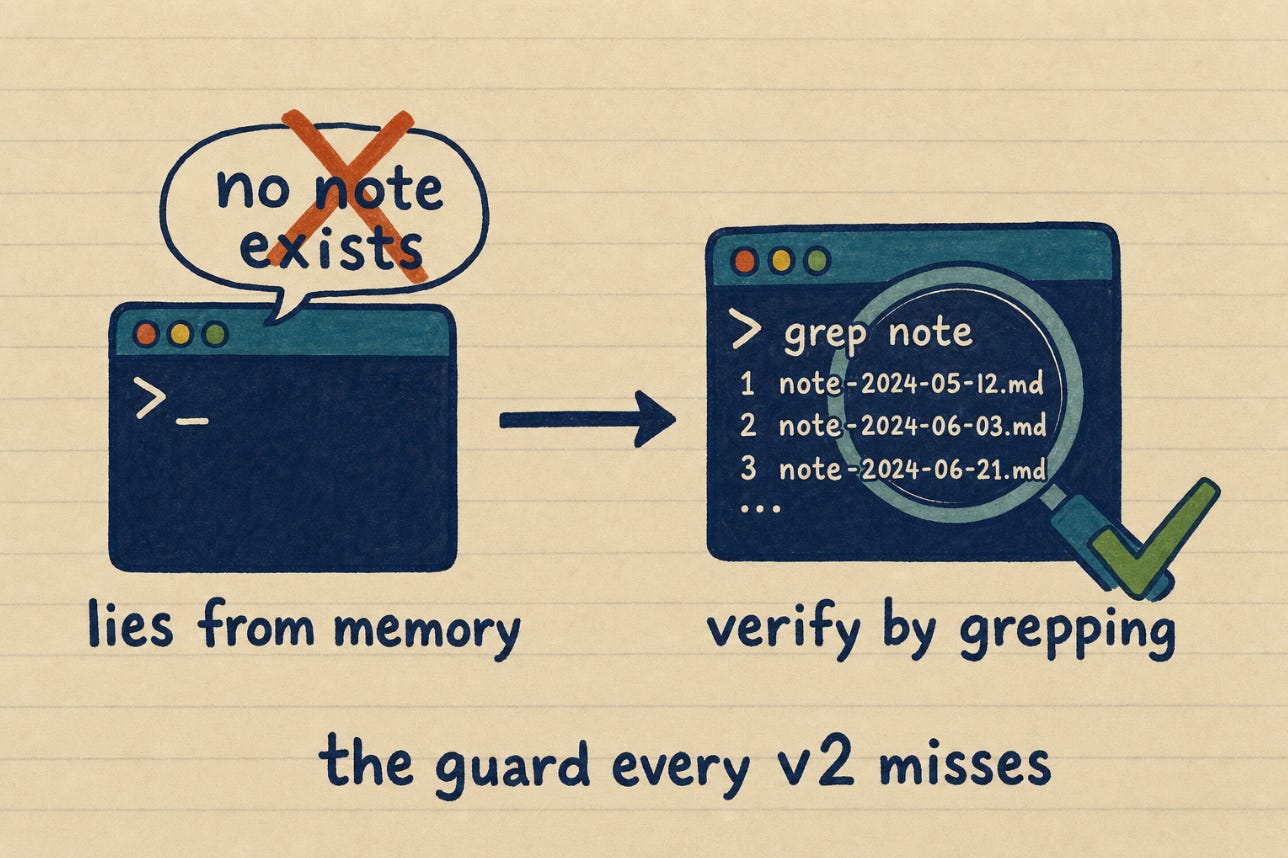
None of them have a real guard against the AI lying about what is in the wiki. I learned this the hard way: when I read through the forks of my repo, a stranger had added the exact thing I lacked. The most common failure is not the AI making up a fact. It is the AI saying “there is no note about that” when there is, because it answered from memory instead of actually searching.
That is the real frontier of v2. Not fancier retrieval. A rule that forces the model to verify presence and absence by listing and grepping, never from memory, before it tells you something does not exist. I am merging that guard in now. No v2 gist I have seen includes it.
The actual lesson
The v2 discourse has the direction backwards. It treats the upgrade as machinery you add: a vector store, a scoring engine, a memory hierarchy.
The version that works is the opposite. It is the smallest set of rules that makes the AI maintain its own truth. Confidence on every claim. Contradictions resolved, not hoarded. Stale notes deleted. An agent that does the maintenance on a schedule. All of that lives in the rules file, and none of it needs a database.
Karpathy’s original insight was that the wiki should be plain markdown the AI owns. The real v2 honors that. It does not drown it in infrastructure.
The full system is open source at obsidian-second-brain. I built it for myself first, and the rules file is the part worth reading. That is where the v2 actually lives.
Frequently asked questions
What is Karpathy’s LLM Wiki?
A pattern Andrej Karpathy shared for letting an AI maintain a small markdown knowledge base. Three layers: raw sources kept immutable, a wiki of notes the AI owns and rewrites, and a rules file that tells it how to ingest, update, and query.
What is “LLM Wiki v2”?
A community label, not an official release. Karpathy’s gist is still the only canonical spec. “v2” refers to additions people propose in their own gists: confidence scores, supersession chains, forgetting curves, hybrid vector search, and lifecycle hooks.
Do you need vector search for an LLM wiki?
No, not at wiki scale. A curated wiki is 50,000 to 100,000 tokens, and grep plus read finds the right note faster and more predictably than embeddings, with no database to host. Vector search earns its place at hundreds of thousands of documents.
Which v2 ideas are actually worth adding?
The governance ones: confidence tags on claims, reconciling contradictions instead of hoarding them, pruning stale notes, and a scheduled agent that maintains the wiki. Each is a few lines in the rules file, not new infrastructure.
How large can an LLM wiki get before it breaks?
It is built for small, curated corpora, roughly 50,000 to 100,000 tokens. Past that, the scale features the v2 gists propose start to matter. At the size where an LLM wiki is most useful, they are weight.
Where can I get a working implementation?
The full system is open source as obsidian-second-brain, a Claude Code skill on GitHub.
Key takeaways
Karpathy’s three-layer pattern (immutable sources, an AI-owned wiki, a rules file) is solid, and v2 does not change it.
“LLM Wiki v2” is a community label, not an official release. Karpathy’s gist is still the only canonical spec.
The v2 ideas worth keeping are all governance: confidence tags, reconciliation, pruning, and scheduled agents. Each costs a few lines in the rules file.
Hybrid vector search is overkill at wiki scale. Grep plus read wins below hundreds of thousands of documents.
The real gap no v2 gist covers is an anti-hallucination guard against false absence: the AI claiming a note does not exist when it does.
The upgrade is rules the AI enforces on itself, not bolted-on machinery.
Further reading
Andrej Karpathy’s original LLM Wiki gist (2026-02)
rohitg00’s LLM Wiki v2 gist (2026-03)
I rebuilt Karpathy’s LLM Wiki. Here’s what’s missing from the original.
Your notes are a graveyard. Here’s how to bring them back to life.
About the author
Eugeniu Ghelbur is an AI Automation Engineer at Single Grain, where he builds production AI systems for marketing and sales workflows. He ships open-source Claude Code skills and writes about AI knowledge management at theaioperator.io. The obsidian-second-brain skill described here is live on GitHub at github.com/eugeniughelbur/obsidian-second-brain, where it has been starred by over 2,300 developers.
Great article. Thanks for sharing your ideas.