

AI Agent Loops Decoded: What's Real, What's Hype
I ran a 112-agent research swarm to fact-check the viral "300 agents" thread. Here's the pattern that's real, the numbers that aren't, and how to build a loop that gets smarter every run.

TL;DR
The hype around AI “loops” and 300-agent swarms is half real. The pattern works: a cheap model generates at volume, a trusted model checks the work, and every run leaves behind a reusable skill so the next run is faster. The headline numbers (”300 agents, 4,000 steps”) are vendor marketing, not benchmarks. Build the loop once and it compounds. You can stand up a working version this week.
Last week a thread tore through builder Twitter. One screenshot: a free, open model running 300 agents in parallel across 4,000 steps from a single prompt, scoring higher on real research than models you pay five times more for. The replies were a mix of “this changes everything” and “this is nonsense.”
I wanted to know which.
So I did the obvious thing. I pointed an agent swarm at the claim about agent swarms. A 112-agent research run, fanning out across primary sources, then a second pass where independent agents tried to refute every claim before it survived. 24 of 25 claims passed. One got killed.
Here is what came back. The pattern is real and it is worth your time. Most of the specific numbers people are quoting are not. And the gap between those two things is where most builders are about to waste a month.
What a loop actually is
For three years the question was which model is smartest. You picked one, typed into a box, got an answer, closed the tab.
A loop kills that question. The unit stopped being the model. It became the system around it.
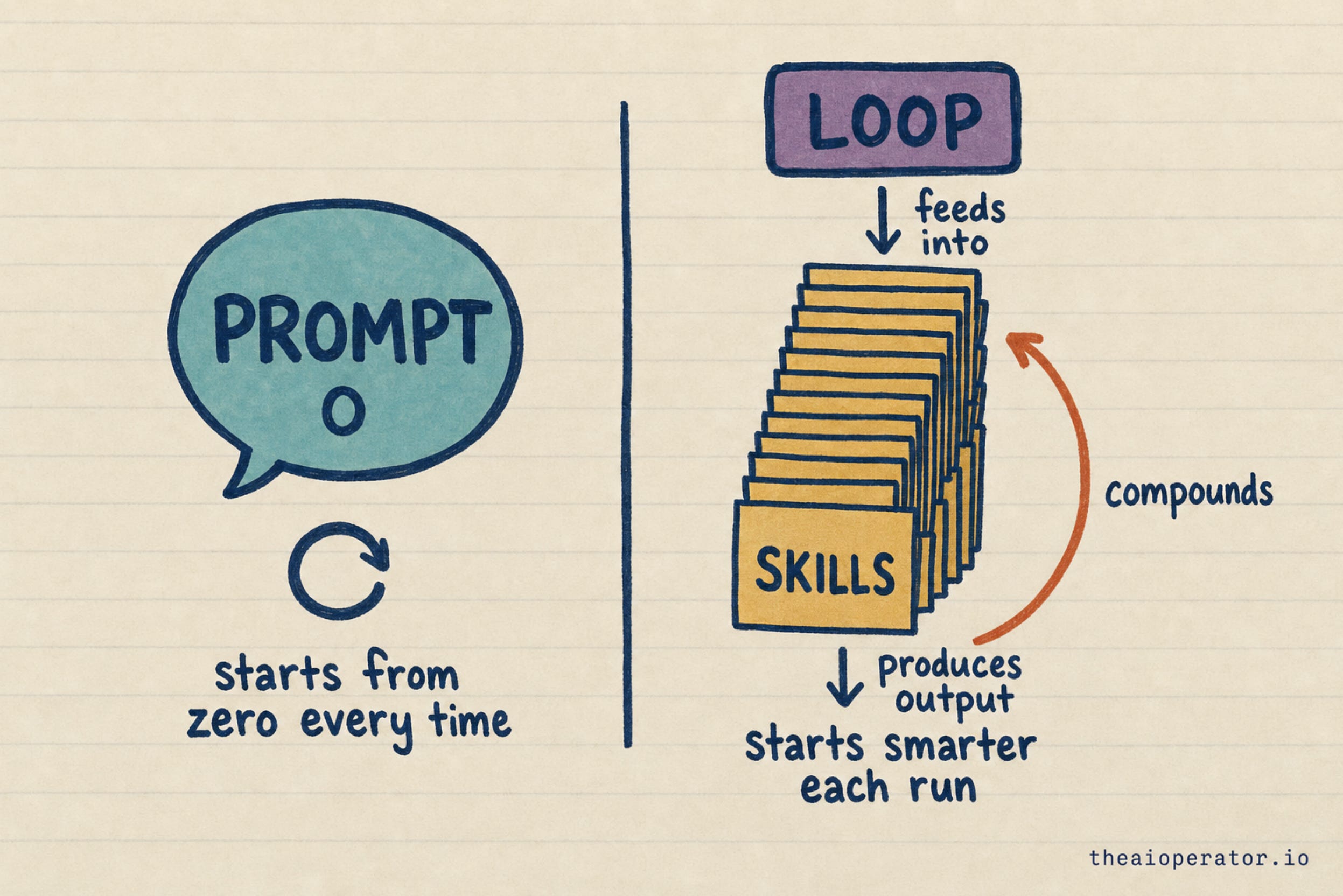
A prompt is a wish. You re-type it every time, and it forgets everything the moment the tab closes. Run number fifty is identical to run number one.
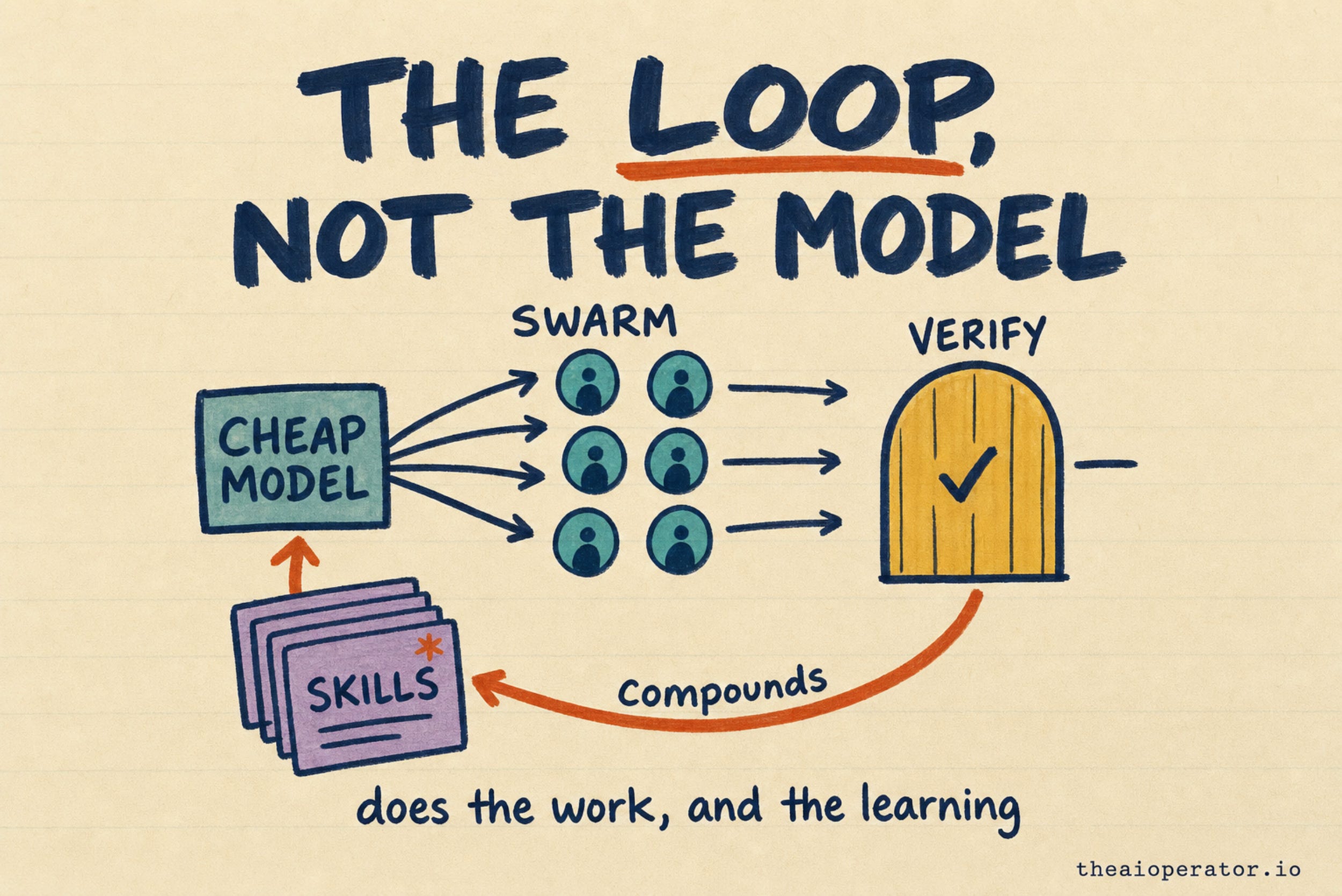
A loop is different. A goal goes in, work comes out, and the system keeps what it learned. The next run starts ahead of the last one, because the run before it left something behind. A reusable skill. A tighter spec. A rule that stops a past mistake from coming back. The single best line from that viral thread holds the whole idea: the system that ran your task yesterday should be smarter than the one running it today.
The model stays frozen. The system compounds. That is the whole game.
The pattern is older than the hype
None of this is new, which is exactly why it works.
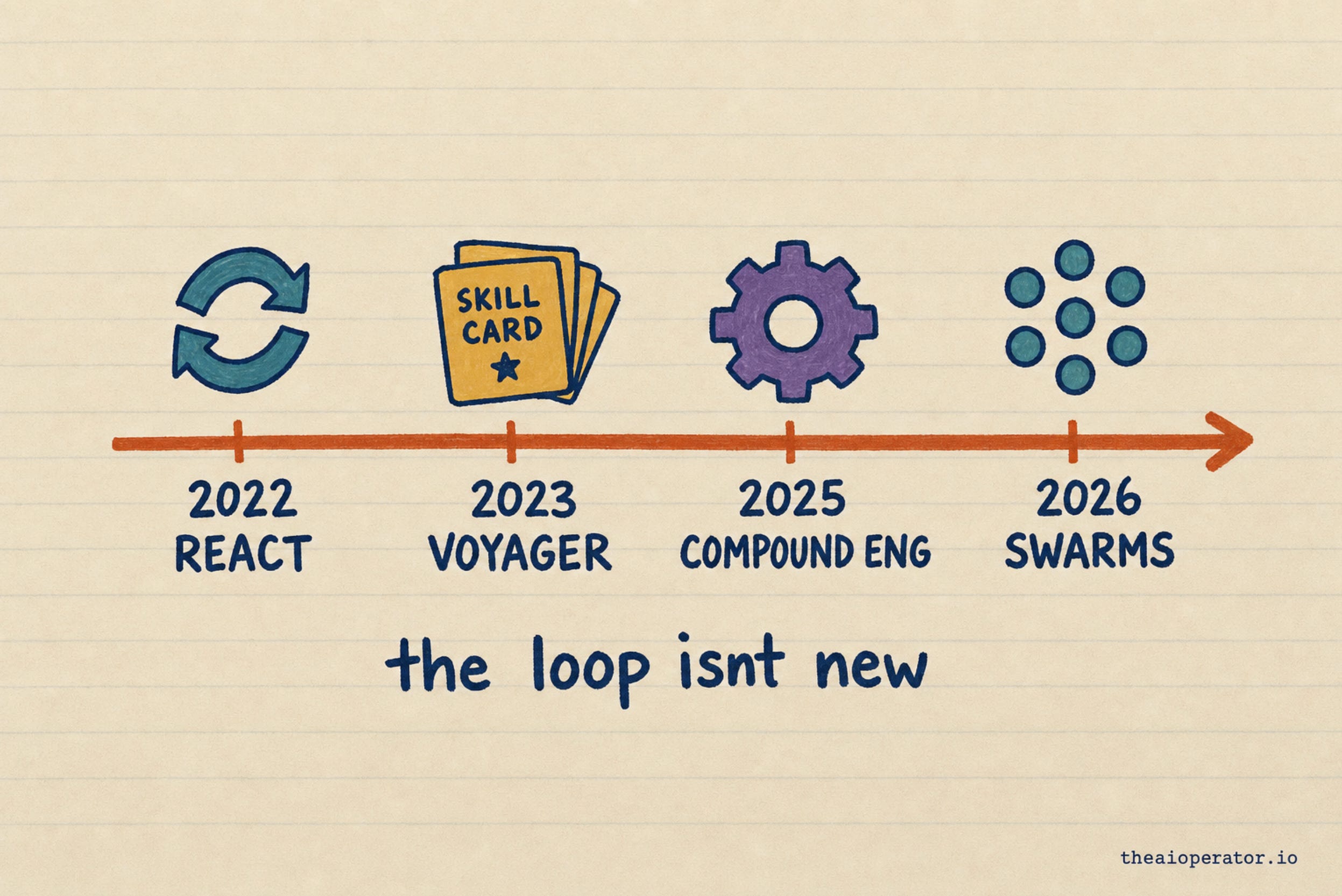
The base loop was published in 2022 in a paper called ReAct: reason, act on a tool, observe the result, repeat. It cut hallucination from 56 percent to near zero on a standard benchmark, simply by grounding each step in a real lookup instead of the model’s guess. Every agent today is its descendant.
A 2023 project called Voyager added the part everyone is now selling. An agent that wrote its skills as reusable code, stored them in a library, and composed them into harder skills over time. Lifelong learning without retraining the model. Sound familiar? “Save the workflow as a skill” is Voyager in a suit.
Then in 2025 a team at Every gave it a name: compound engineering. Building systems where each run makes the next one faster, safer, and better. This is the same insight I built my own setup on, and the same one behind rebuilding Karpathy’s LLM Wiki: a model does not get bored maintaining its own knowledge, so the knowledge compounds instead of rotting.
If a term in here is new to you, I wrote a plain-language guide to the core AI concepts that pairs well with this post.
Why split it into a swarm
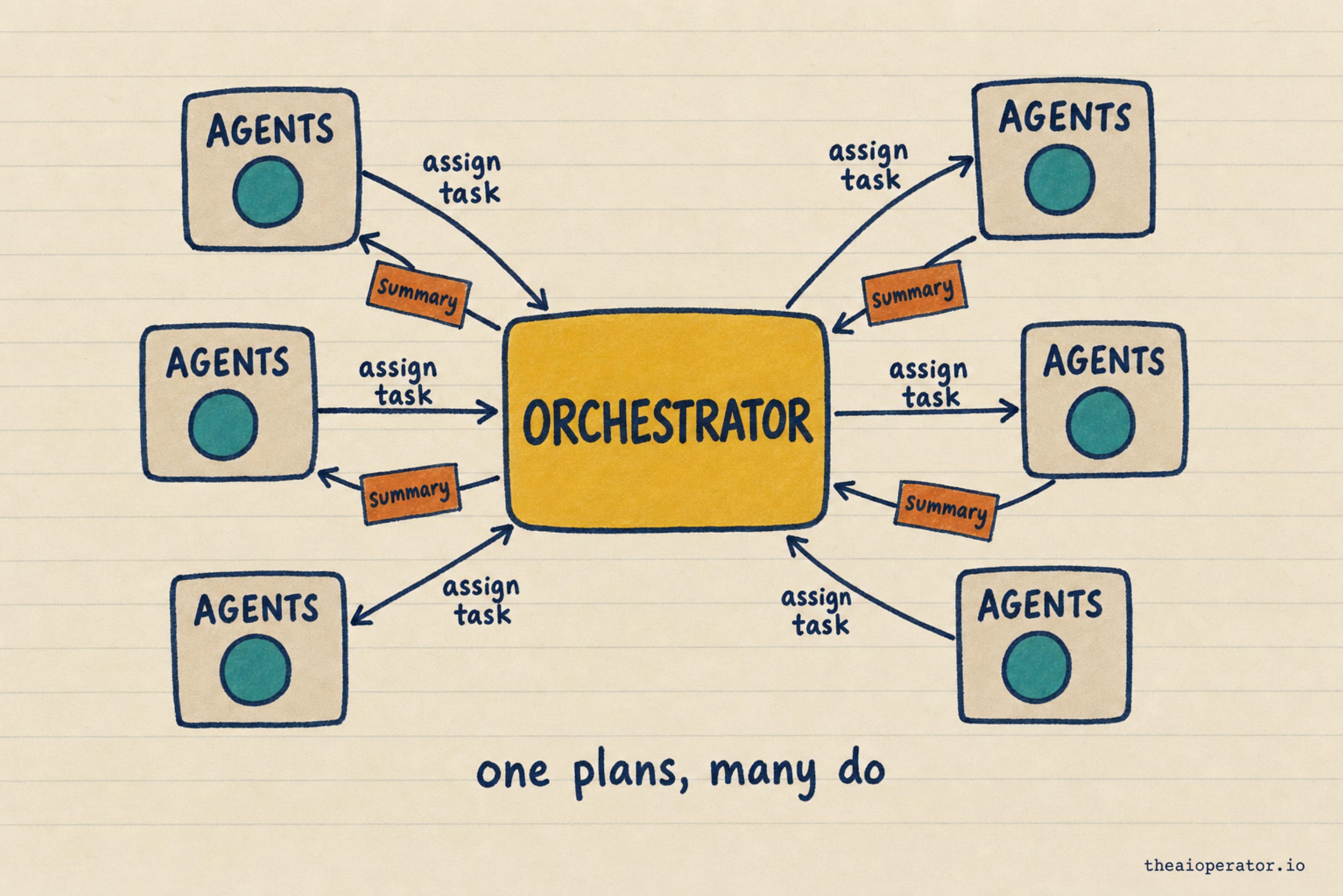
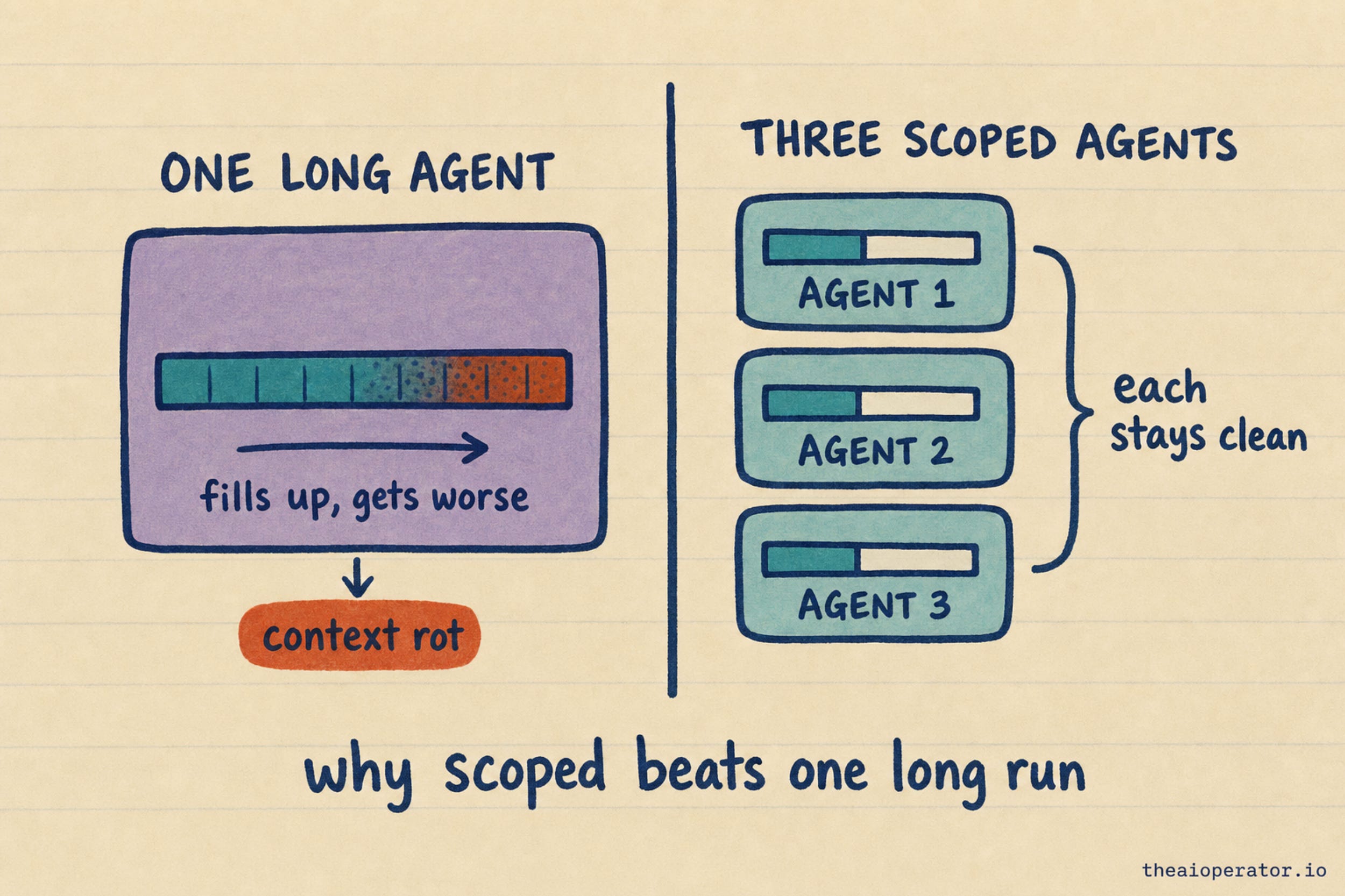
Why fan a task out to many agents instead of asking one model to do it all? Because one agent on a long task fills its context window until it starts to drift. Researchers call it context rot. Past a point, every step gets a little worse, because the model is reasoning over a window stuffed with its own earlier output.
A swarm fixes this. A coordinator splits the job, each agent works on one piece in its own clean context, and only a short summary flows back to be assembled. Nobody drowns in a giant context, so the system holds up on work that would break a single agent. That is the real reason the parallel setup wins, and it has nothing to do with the agent count on the marketing page.
The one move that separates a loop from a toy
Here is the part most threads skip, and it is the most important one.
A swarm of cheap agents will produce confident, under-cited work. Run enough of them and some will quietly contradict each other. “Looks done” and “is correct” are different planets. The first wave of autonomous agents in 2023, the AutoGPT era, failed for exactly this reason: nothing was checking the work.
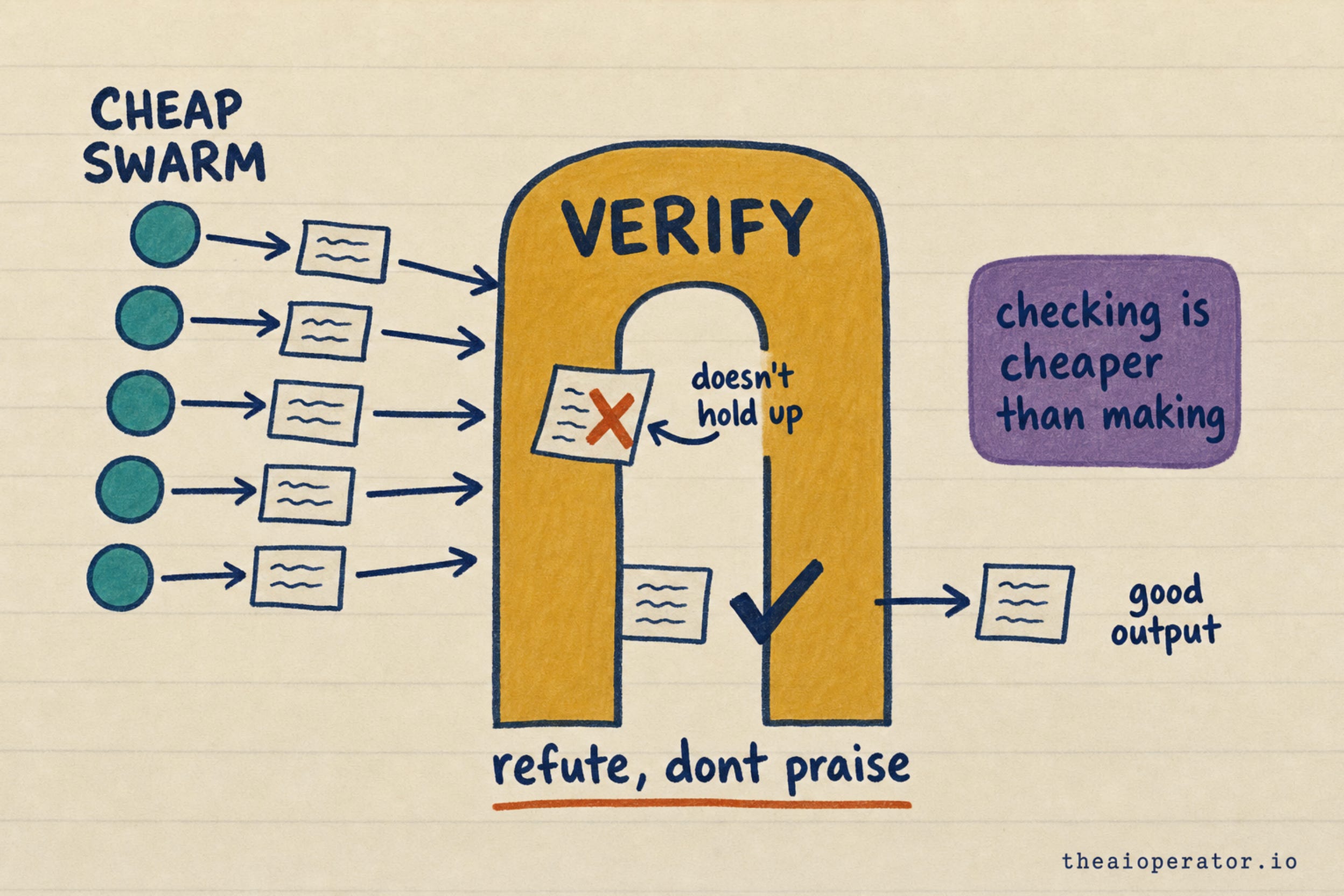
The fix is a verify gate. You point a second, trusted model at the output and tell it one thing: refute, do not praise. List what is wrong.
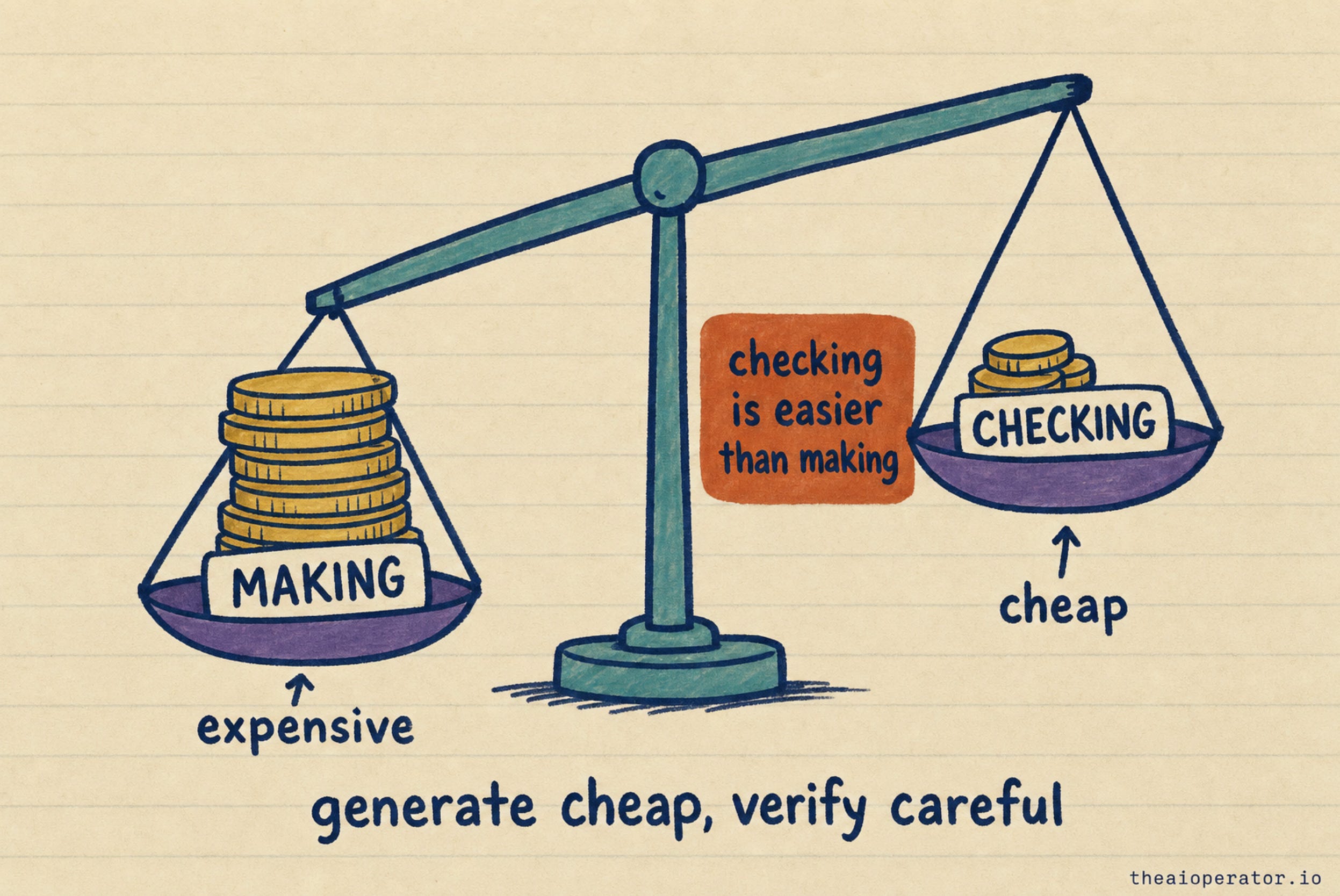
Why this works comes down to a single asymmetry. Checking an answer is easier than producing it. So you generate cheap at high volume, and you spend your expensive, careful tokens only on the gate that catches the silent flaw. A loop without that gate is just AutoGPT again, now at scale and on your invoice.
This is the real shape of the hybrid stack everyone is excited about. A cheap open model does the work. A premium model sits at one gate and keeps it honest.
What’s real, and what’s vendor marketing
This is where the swarm I ran earned its keep. Three findings matter.
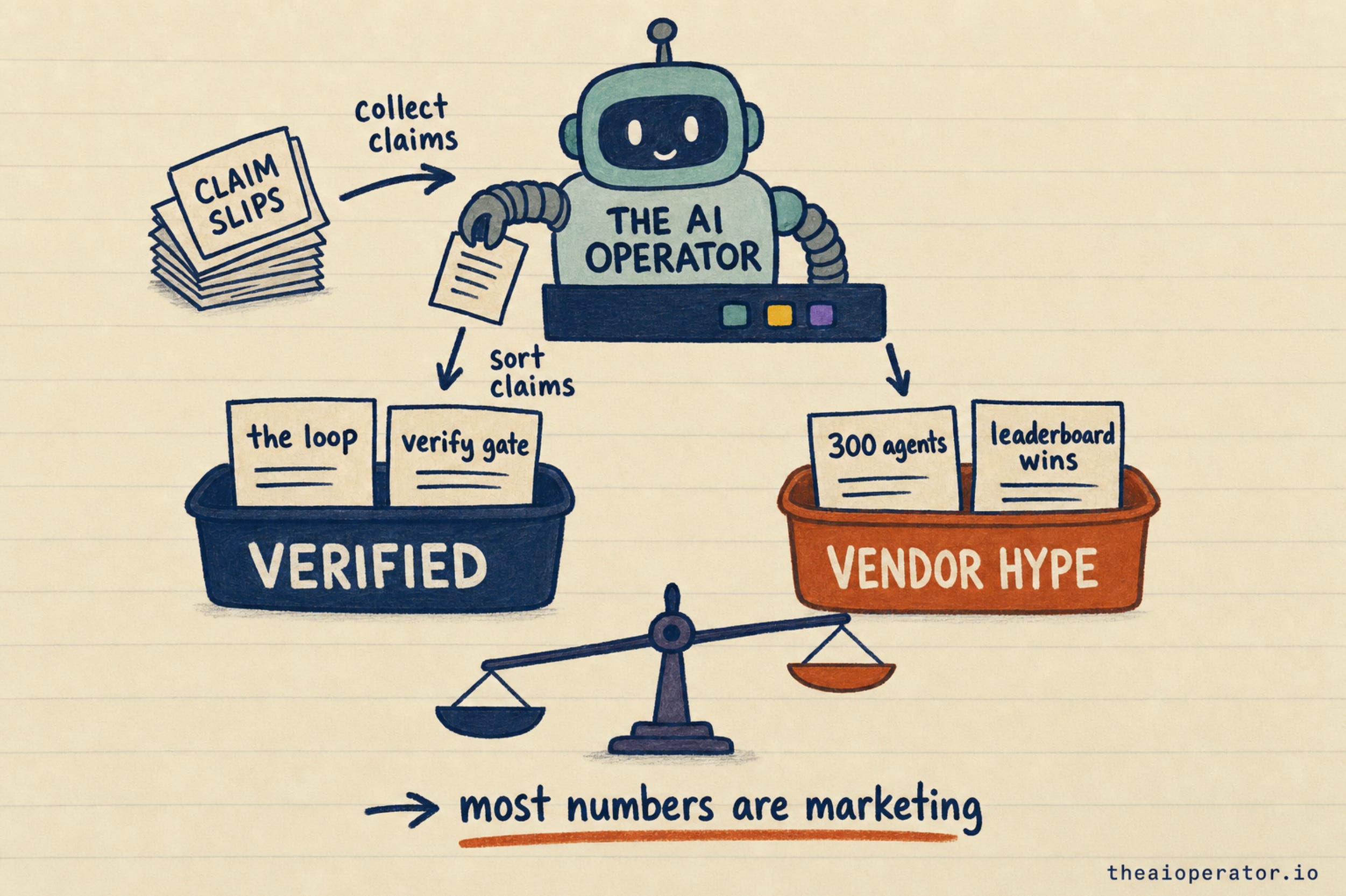
The viral “300 agents, 4,000 steps” is a capability ceiling, not a benchmark. It is a line in the open model’s own product page. The vendor’s actual public demos topped out around 100 agents on one task and about 30 on another. The “4,000” came from a separate, unrelated run. It describes what the system can be told to attempt, not the quality of what comes out at that size.
The famous “this model is four times less likely to pass its own code flaws” line is real, but softer than it sounds. It does not appear in the technical safety report at all. I checked the full document. It lives in a launch announcement, it is self-reported with no published method, and it measures honesty, that the model flags its own uncertainty, not that the code it writes is four times better.
The head-to-head benchmark numbers people are reposting, where the open model beats the big paid ones on specific tests, did not hold up. That is the one claim my refute pass killed. They could not be substantiated across sources. The open-versus-closed gap is genuinely unsettled, not won.
None of this means the tools are bad. The open model is genuinely open-weight and genuinely cheap, which is the part that actually matters. Cheap tokens are what make “run it twice and throw the first attempt away” a sane thing to do. That is the same shift that hit the field when DeepSeek landed. The economics are the story, not the leaderboard screenshots.
Why it compounds, and why that is the real moat
The reason to build a loop instead of a better prompt is defensibility.
Anyone can rent the same model you use. Nobody can copy three things: your skill library, the documents you fed in to make the output sound like you, and your constraints file, the running list of every mistake the verify gate caught and turned into a permanent rule. Those were built from months of your real runs.
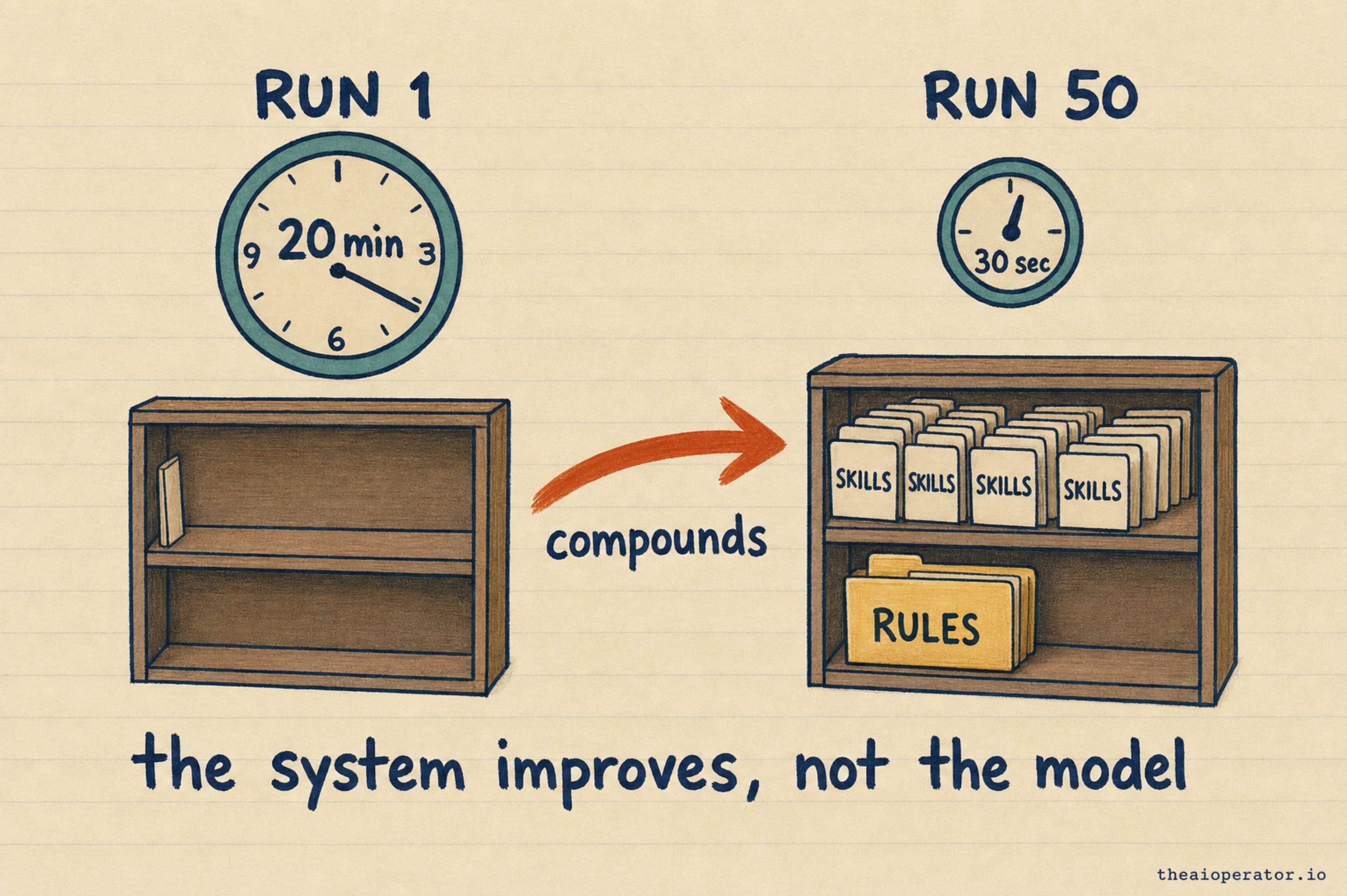
That is why the first run takes twenty minutes and the fiftieth takes thirty seconds, sharper each time. The model did not get smarter. Your system did. I have watched three model generations come and go while the same files kept running, and each one got better at the job, not because of the model, but because the scaffolding around it kept absorbing what I learned.
“Self-improving” does not mean the weights retrain on your runs. They do not. The system around the model improves. Anyone telling you otherwise is selling something.
When not to build one
I am not going to pretend swarms are for everything, because they are not, and the honest version of this is what separates builders from resharers.
The strongest counter-argument is simple: the same loop that compounds wins also compounds errors. With no human-anchored ground truth, a flawed spec drifts and the system gets confidently wrong faster. The mitigations are the verify gate, the constraints file as a ratchet, and a human who stays on the question and the final decision.
Cost is the other catch. The lab that builds these said it plainly: running parallel agents this way burns roughly fifteen times the tokens of a normal chat, so it only pays off on high-value work. And it is a poor fit for tasks that need one coherent thread of reasoning, like writing a single long argument, or anything where the parts depend tightly on each other. Swarms shine on work you can split, run in parallel, and check: research, monitoring, broad data gathering. Not everything.

Build one this week
You do not need the 300-agent setup to get the benefit. Here is the smallest version that is a real loop and not a toy.
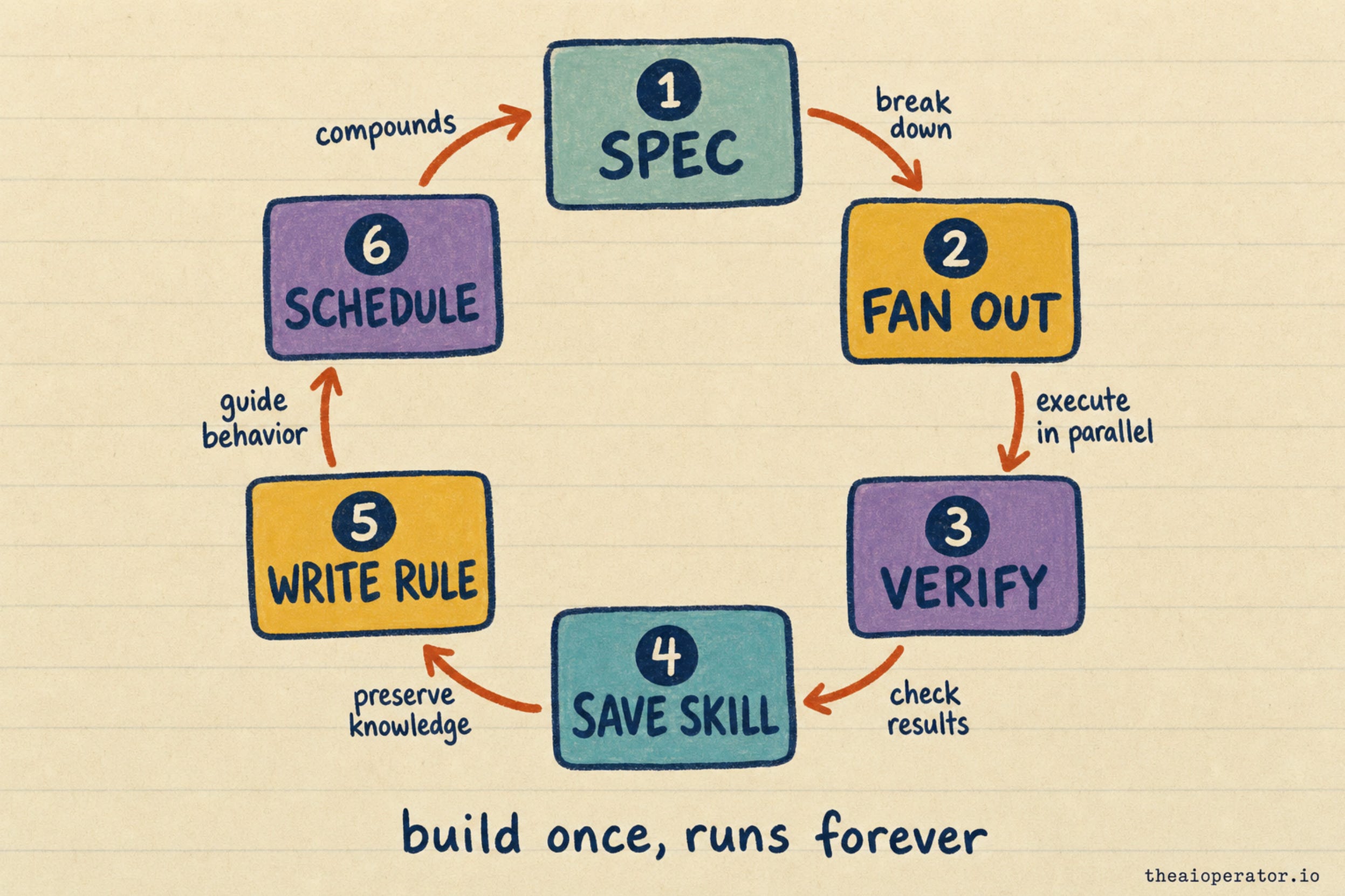
Start with a spec, not a prompt. Pick one task you actually repeat, like a weekly competitive brief. Write down what to collect, which sources count, the exact output format, and what to do when sources conflict. Treat the system like a contractor, not a genie.
Fan the independent parts out to separate agents, each working in its own clean context and handing back a short summary. Then add the gate: a second pass that tries to tear the output apart before you trust it. Capture the whole thing as a reusable skill so next week starts from it. Every flaw the gate catches becomes one line in a constraints file the system reads first, every time. Once it is stable, put it on a schedule and let it surface only the result and anything that looks off.
That is the loop. The only human left in it is the question you set and the decision you make on the answer.
I am not theorizing here. I maintain an open-source second brain that has been cloned and starred by over 2,500 developers. It is a loop: it reads its own notes, does the work in steps I can check, and writes back what it learned so the next run starts smarter. Plain files, in git, no framework. The model underneath has changed three times. The loop kept running.
Build it once. Verify it. Distill it. Then watch it get cheaper and sharper every single time you run it.
Frequently asked questions
What is an AI agent loop?
It is a system where a model does a task, checks the result, and saves what it learned so the next run starts from a better place. Unlike a one-off prompt, a loop accumulates skills and rules over time, so it improves with use even though the model itself never changes.
What is an AI agent swarm?
It is many agents running in parallel on pieces of one task. A coordinator splits the job, each agent works in its own context and returns a short summary, and the coordinator assembles the result. It beats a single agent on tasks you can break apart, because each piece gets a clean, focused context.
Can an open model really run 300 agents at once?
That number is the vendor’s stated maximum, not a measured benchmark. Real public demos ran closer to 30 to 100 agents. The capability to orchestrate many agents is real. The “300 and 4,000 steps” figure is a marketing ceiling, so treat it as such.
Is “self-improving AI” actually the model learning?
No. The model’s weights stay frozen. What improves is the system around it: a growing library of saved skills, fed documents, and a constraints file of past mistakes. The loop gets smarter. The model does not. Anyone implying live retraining from your runs is overselling.
Why do I need a verify gate?
Because a swarm produces confident, under-checked output, and some of it is quietly wrong. A second model told to refute the work catches flaws before they get saved as a permanent skill. Checking is cheaper than generating, which is why this step pays for itself.
When should I not use an agent swarm?
Skip it for tasks that need one coherent line of reasoning, for tightly interdependent work, and for low-value jobs where the extra cost is not worth it. Parallel swarms can use around fifteen times the tokens of a normal chat, so they fit high-value, splittable, checkable work.
Key takeaways
An AI loop beats a prompt because it compounds: every run leaves behind a skill, a document, or a rule that makes the next run faster and sharper, while the model stays frozen.
The pattern is not new. ReAct (2022) gave us the base loop, Voyager (2023) gave us reusable skills, and “compound engineering” (2025) gave it a name.
A swarm beats one long agent because each piece runs in its own clean context, avoiding the context rot that degrades a single agent on a long task.
The verify gate is the one non-optional move. A cheap model generates at volume, a trusted model refutes the output, because checking is easier than generating.
The viral numbers are vendor marketing. “300 agents, 4,000 steps” is a capability ceiling, not a benchmark, and the head-to-head leaderboard claims did not survive fact-checking.
The real advantage of open models is cost, not benchmarks. Cheap tokens make “run it twice, throw the first away” rational, the same shift DeepSeek triggered.
Swarms are for splittable, checkable, high-value work. They burn roughly fifteen times the tokens of a chat and are a poor fit for single coherent arguments or tightly coupled tasks.
Further reading
Anthropic, Building Effective Agents (the canonical taxonomy of workflows versus agents, and the orchestrator-worker and evaluator-optimizer patterns). Search “Anthropic Building Effective Agents”.
Yao et al., ReAct: Synergizing Reasoning and Acting in Language Models (ICLR 2023, the origin of the agent loop). On arXiv.
Every, the compound engineering essays by Kieran Klaassen (where the self-improving-system thesis got its name).
Cognition AI, Don’t Build Multi-Agents (the strongest skeptic case, on when parallel agents hurt you).
The obsidian-second-brain skill on GitHub: github.com/eugeniughelbur/obsidian-second-brain
About the author
Eugeniu Ghelbur is an AI Automation Engineer at Single Grain, where he builds production AI systems for marketing and sales workflows. He ships open-source Claude Code skills and writes about AI knowledge management at theaioperator.io. The obsidian-second-brain skill described here is live on GitHub at github.com/eugeniughelbur/obsidian-second-brain, where it has been starred by over 3,000 developers.