

The CLAUDE.md behind a tool 3,000 developers use
This one file is the difference between an AI you can trust to run real work and one you babysit line by line. Here is my actual file, what I deleted, and the rule that keeps it working.

TL;DR
A CLAUDE.md is the operating manual an AI coding agent reads before every task. Get it wrong and the agent is unreliable. Get it right and you can hand it real work.
I run one across an open-source tool that 3,000 developers have adopted. Every real win came from deleting, not adding.
Keep it short and enforceable, push detail into skills and commands, and never write a rule the agent can’t actually follow.

If you have ever asked an AI to do real work, you have felt the problem underneath this post. You explain what you want once. The next time, it has forgotten all of it. You re-explain the same context, the same rules, the same “no, not like that.” Every session starts from zero, so you never quite trust it with anything that matters.
That distrust is the real ceiling on AI at work right now. Not the model’s intelligence. The fact that it forgets, so a person has to sit next to it and check.
For AI coding agents there is a fix, and it turns out to be most of the game. It is a plain text file called CLAUDE.md. The agent reads it before it touches anything, so your standing rules load automatically and the same mistakes stop repeating. That file is the line between an assistant you check constantly and one you can point at a task and walk away from.
I ran one across obsidian-second-brain, an open-source tool I built for myself and then watched thousands of strangers adopt. Roughly 3,000 developers now run it. It is the same pattern I used when I rebuilt Karpathy’s LLM wiki gist into a working system.
Here is what actually holds up, after the file got worse before it got better.
What a CLAUDE.md actually is
Start with the mental model, because most people get it wrong, and the wrong model is why their file bloats.
A CLAUDE.md is not documentation. It is not a README. It is the set of standing instructions the agent loads into its working memory on every run, before it reads a single line of your code. Anthropic’s own docs describe it as memory that persists across sessions. That is the right way to hold it in your head: it is the agent’s memory, and memory has a budget.
So there is only one question that matters for any line in the file. Does the agent need this loaded every single time, or not? If the answer is no, that line is not helping. It is crowding out the lines that are.
Why more rules made it worse
Search “CLAUDE.md best practices” and you get the same advice everywhere. Add a rules section. Add your tech stack. Add coding standards. Add a testing policy. Add, add, add.
I did all of it. My file grew past 300 lines. And the agent got less reliable, not more.
The reason is simple once you see it. A bloated CLAUDE.md is a wall of text the model skims. Bury the three rules that actually matter inside forty rules that don’t, and the model weights them all the same. You did not give it a manual. You gave it noise, and noise is what it acts on.
The strongest outside voice on this agrees. HumanLayer runs a roughly 60-line CLAUDE.md on purpose and argues most of what people cram in there is a linter’s job. They are right, and the shift from long to short is the single biggest quality change I made.

What I deleted
The turnaround came from cutting. Here is what left the file.
The linter rules. “Use single quotes, max line length 100, sort imports.” That is not the agent’s job, it is the formatter’s job. I deleted every style rule a tool already enforces and let the tool fail the agent instead. The tool never forgets and never skims.
The obvious rules. “Write clean code. Add tests where appropriate.” The agent already tries to do this. A rule that restates the default does nothing but take up space and dilute the rules that don’t.
The aspirational rules. This is the sneaky one. “Always achieve 100% test coverage.” I was never going to enforce that, and the agent could not verify it, so the line was pure decoration. If you would not fail the work over a rule, it does not belong in the file.
What stayed is the handful of things specific to my project and non-obvious. Use uv, not pip. Vault writes follow the AI-first rule. Never touch these three protected files. Sentence-case headers, no em-dashes. Rules the agent would get wrong without being told, and that I actually check.
The three places instructions live
This is the part almost nobody writing about CLAUDE.md gets to, and it is the one that changed everything for me.
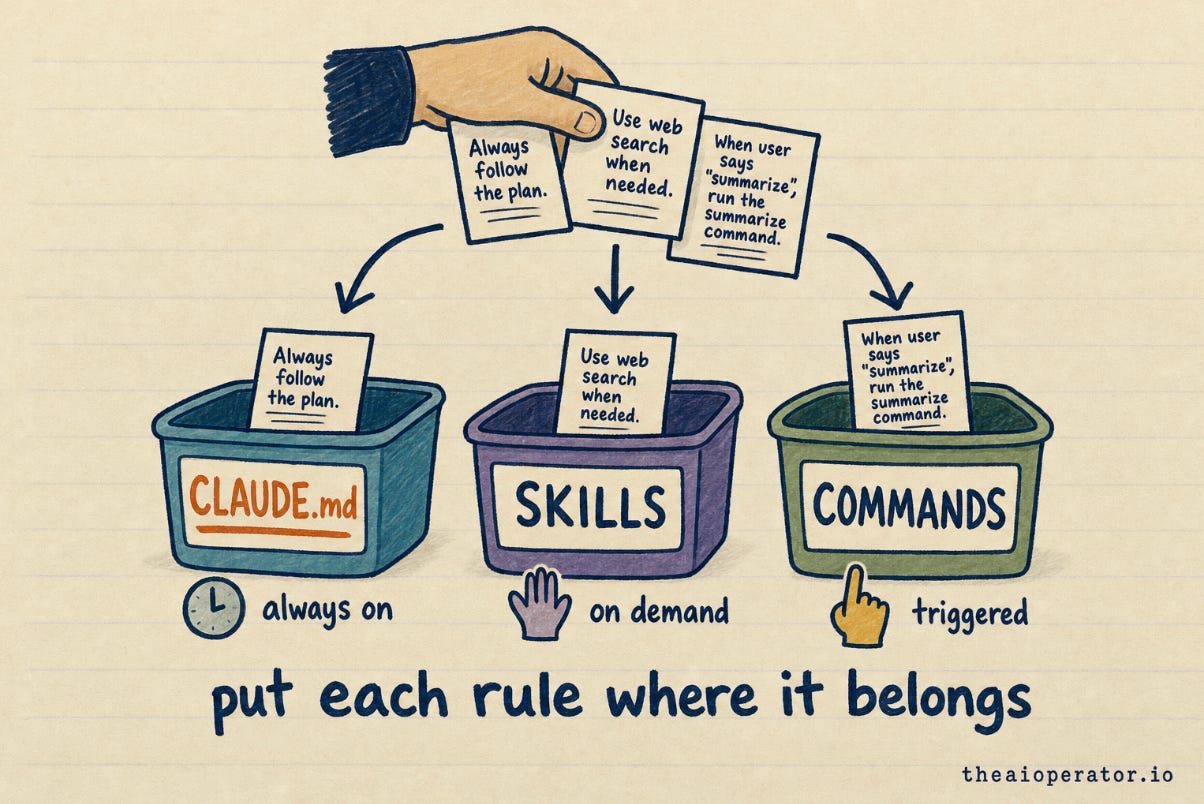
You have three places to put instructions, not one.
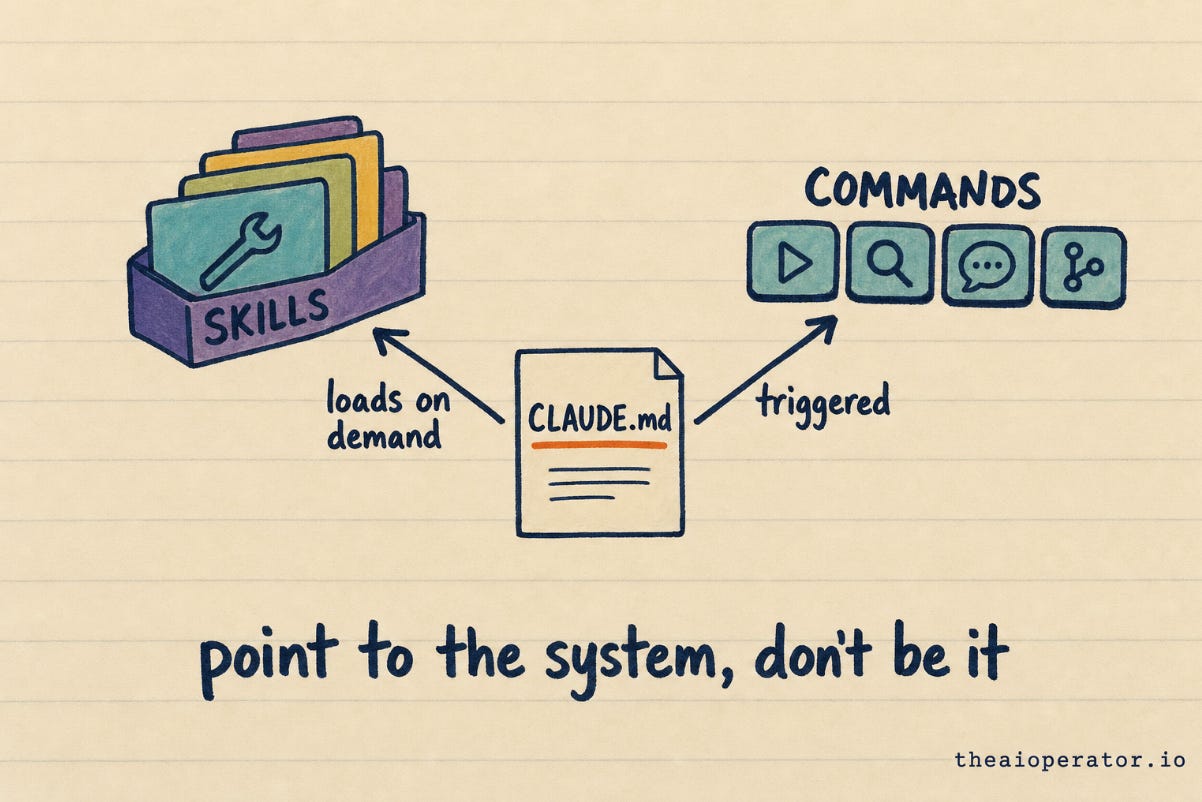
CLAUDE.md is always on. It loads every session, so it pays a permanent tax on the agent’s memory budget. Reserve it for the rules that apply to almost every task.
Skills load on demand. When the work matches a skill, the agent pulls in that detailed instruction set, and only then. So the deep procedure for one kind of task lives in a skill, and it costs nothing until the moment it is needed.
Commands are explicit workflows you trigger by name. The multi-step recipe you run the same way every time lives in a command, where you invoke it deliberately.
Once I understood this, the CLAUDE.md shrank on its own. Most of what I had crammed into it was not always-on knowledge. It was task-specific detail that belonged in a skill, or a workflow that belonged in a command. The same instinct that makes a good second brain rewrite itself instead of piling up notes applies here. Structure beats volume. A small file that points to the right place beats a big file that holds everything.
The one test that decides every line
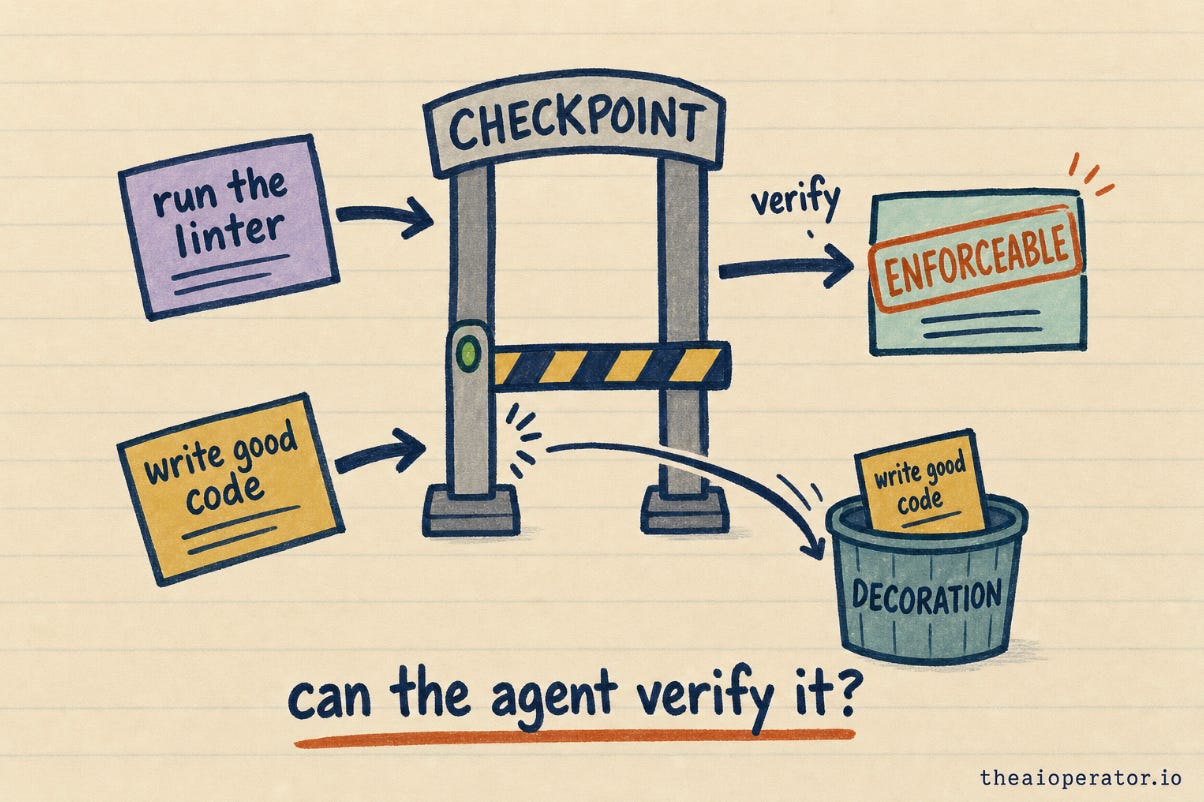
Here is the test I run on every line now. Can the agent verify it did this, and would I fail the work if it didn’t?
A rule that passes both is enforceable. “Run the voice linter before saving, the file must pass.” The agent runs it, sees pass or fail, and I can check the file afterward. That rule works because there is a real check behind it.
A rule that fails the test is decoration. “Write thoughtful, high-quality code.” There is nothing to verify and nothing to fail. It reads well and does nothing.
The enforceable rules are almost always the specific ones. A named command to run. A file that must not change. A format the output has to match. The vague ones feel productive to write, and they are the first thing the model drops under load. If you want the agent to hold a line, give it a line it can check.
What this means if you don’t write code
If you run a team instead of a codebase, this is the part that matters.
The reason most companies cannot trust AI with real work is not the model. Every team has access to the same models. The difference is whether anyone wrote down the standing rules the AI needs, in a form it reads every time and a human can actually check. That is what a good CLAUDE.md is. It is institutional memory for the agent.
So the skill that separates people getting real leverage from AI is not prompting. It is knowing which rules to write down, keeping the list short enough that all of it gets read, and making every rule checkable. That is a discipline, and it is the same discipline whether you are running one agent or a whole team of them.
Strip it all back and a CLAUDE.md is one thing. It is a compression of the decisions you are tired of re-explaining. Not everything you know. The specific, non-obvious calls the agent would get wrong and that you would otherwise correct by hand every single time. Written down once, loaded automatically, kept small enough that every line still gets read.
Mine is under 150 lines now and does more than the 300-line version did. The detail did not disappear. It moved to skills and commands, where it loads when it is needed instead of taxing every task.
Add less. Delete more. Point to the real system instead of trying to be it.
Frequently asked questions
What is a CLAUDE.md file? It is a markdown file an AI coding agent like Claude Code reads automatically before every task. It holds your project’s standing rules and conventions so the agent does not start each session from scratch.
Where do I put CLAUDE.md? In your repo root for project-wide rules. Claude Code also reads a personal one at ~/.claude/CLAUDE.md that applies across all your projects, and you can nest one in a subfolder for rules that only apply there.
How long should a CLAUDE.md be? Short. Aim well under 150 lines. Every line loads on every task and competes for the model’s attention, so length has a real cost. If a rule is not needed on almost every task, move it to a skill or command.
What should I not put in CLAUDE.md? Anything a linter or formatter already enforces, anything that just restates the model’s default behavior, and any aspirational rule you would not actually fail the work over.
What is the difference between CLAUDE.md, skills, and commands? CLAUDE.md is always loaded. Skills load on demand when the task matches. Commands are explicit workflows you trigger by name. Detail belongs in skills and commands, not in the always-on file.
Does CLAUDE.md work with AGENTS.md? They serve the same purpose for different tools. AGENTS.md is the cross-tool standard several agents read. The discipline is identical for both: keep it short, keep it enforceable.
Key takeaways
A CLAUDE.md is the operating manual your agent reads before every task, and it is the real difference between an AI you babysit and one you can trust with work.
Bloat is the main failure mode. A long file buries the rules that matter inside rules that don’t, and the model weights them all the same.
The biggest wins come from deleting: linter rules, obvious rules, and aspirational rules you will never enforce.
Instructions live in three places. CLAUDE.md is always-on, skills load on demand, commands are triggered by name. Most CLAUDE.md content actually belongs in the other two.
The test for any line: can the agent verify it, and would you fail the work if it didn’t? If not, it is decoration.
The skill is not prompting. It is knowing which rules to write down and keeping the list short enough that every line still gets read.
Further reading
Claude Code memory and CLAUDE.md - Anthropic’s official reference on how the file loads.
Writing a good CLAUDE.md - HumanLayer’s short-file thesis, the strongest outside take.
AGENTS.md - the cross-tool standard, same rules for other agents.
I rebuilt Karpathy’s LLM wiki gist - the working system this CLAUDE.md runs.
Karpathy’s LLM Wiki v2: what to keep, what to skip - why structure beats volume in an AI-maintained system.
obsidian-second-brain on GitHub - the open-source repo, CLAUDE.md and all.
About the author
Eugeniu Ghelbur is an AI Tooling Engineer who builds production AI systems. He ships open-source Claude Code skills and writes about AI knowledge management at theaioperator.io. The obsidian-second-brain skill described here is live on GitHub at github.com/eugeniughelbur/obsidian-second-brain, where it has been adopted by over 3,000 developers.